摘要
基于人工智能的漏洞挖掘方法,检测模型的精确一方面取决于模型的选择,另一方面取决了数据(源代码特征提取与表示)。如何有效全面的进行源代码的表示,也是研究的重点之一,笔记归纳总结了现有的源代码层面的特征提取与表示方法,供大家研究提供参考。
基于数据流的Tokens化
TAP: A static analysis model for PHP vulnerabilities based on token and deep learning technology
根据PHP的特性,基于PHP原始Token机制解析字符串、数字和函数。然后统一化这些Token,使用预定义的“Uniform tokens”进行表示所有的Token name以及函数名。最后使用word2vec进行向量化。

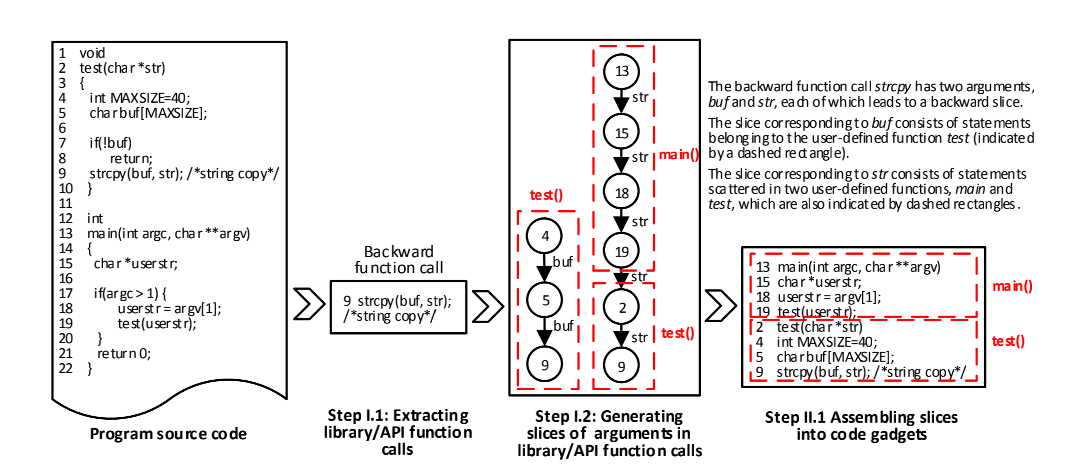
基于library/API的程序切片
VulDeePecker: A Deep Learning-Based System for Vulnerability Detection
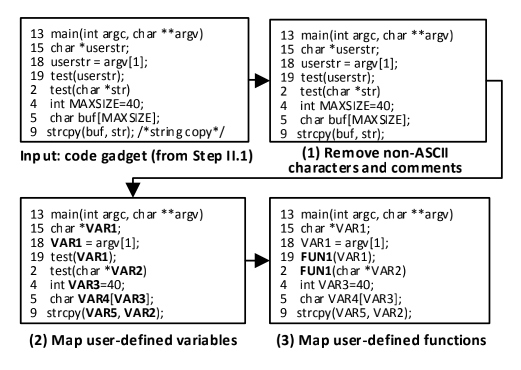
首先定位到源代码中的API调用函数,然后通过调用函数输入的参数进行回溯,找到相关的代码行,然后再将提取出的代码行重组起来,最后切片出的特征代码就是与漏洞关联较大的语句,有效的过滤了无关的代码行(定义等语句),同时保证其在数据依赖性或控制依赖性方面在语义上是相互相关的。下一步通过移除非ASCII字符和注释,替换用户自定义的变量和函数名完成预处理得到最后的代码特征。编码方法使用word2vec。在提取library/API函数调用时分为两类:
- 前向调用:
前向library/API函数调用是直接从外部输入接收一个或多个输入的函数调用,例如命令行、程序、套接字或文件。 - 后向调用:
后向library/API函数调用是指不直接从程序运行的环境接收任何外部输入的函数调用,例如strcpy(buf,str)。
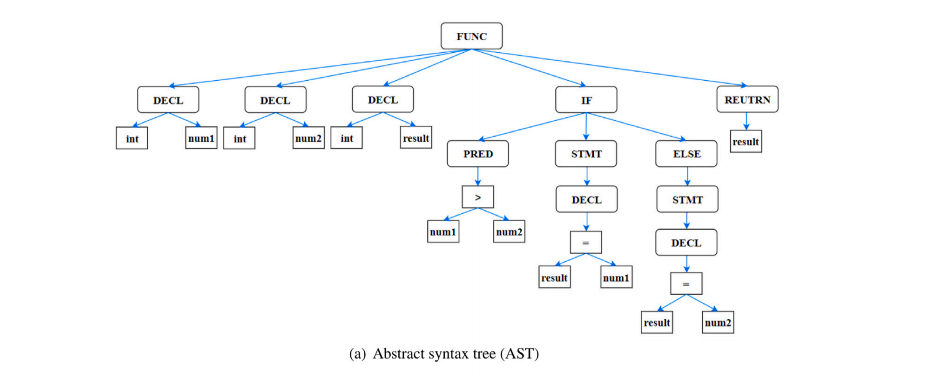
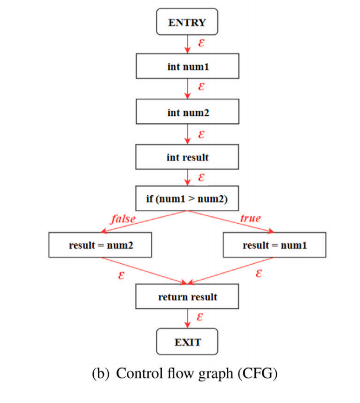
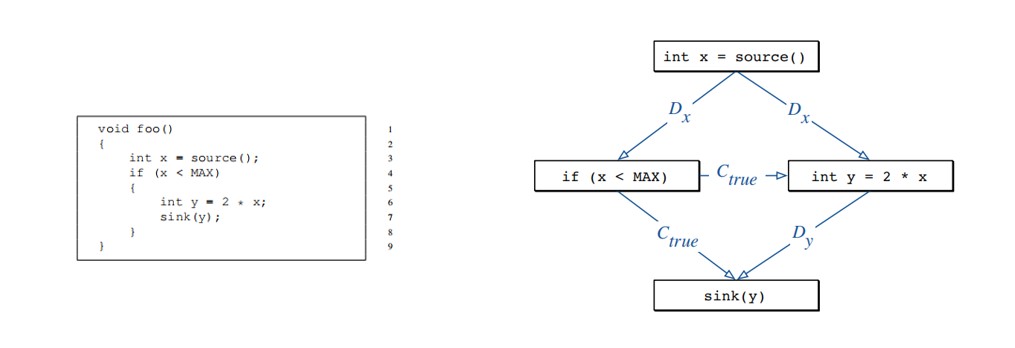
AST、CFG、DFG、CCG都是基于下图的代码样本构建的。

AST(抽象语法树)
BGNN4VD: Constructing Bidirectional Graph Neural-Network for Vulnerability Detection
将每个源代码文件解析为一个抽象语法树(AST)。这个过程忽略了注释、空行、标点符号和分隔符、大括号、分号和圆括号)。AST的每个节点都表示源代码中的结构。用AST类型来标记每个树节点(字段声明、方法声明、BlockStmt和WhileStmt)。
Int -> IntegerLiteralExpr, string -> StringLiteralExpr.然后将每个AST节点的标签名称映射成一个固定长度的连续值向量。
CFG(控制流图)
BGNN4VD: Constructing Bidirectional Graph Neural-Network for Vulnerability Detection
描述了在执行过程中可能遍历的所有路径,在CFG中,节点表示语句和条件,它们通过有向边连接,以表示控制的传递。
CDG(控制依赖图)
https://www.codetd.com/es/article/13546350
控制依赖图由控制流图和FDT(Forward dominance Tree)产生。
在FDT前向支配树中对于节点n来说,从根节点到结点n所在路径上的结点都严格支配结点n,例如节点6->5->2,节点6,5都严格支配着节点2。该路径上离结点n最近的结点叫做结点n的直接支配结点。
CDG代表着程序入口对每条语句的可达性,而CFG代表着代码语句与相邻语句之间的控制关系。
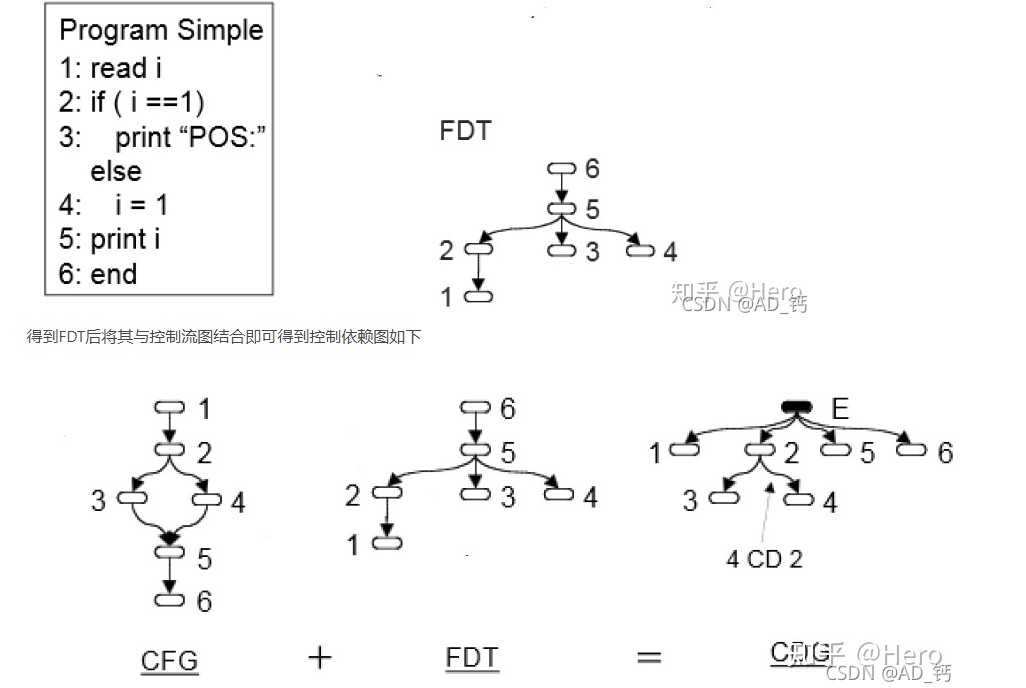
DFG(数据流图)
BGNN4VD: Constructing Bidirectional Graph Neural-Network for Vulnerability Detection
跟踪整个CFG中变量的使用情况,数据流是面向变量的,任何数据流都涉及到对某些变量的访问或修改。
DDG(数据依赖图)
DDG和DFG本质上是一样的,都是追踪程序中变量的使用情况。
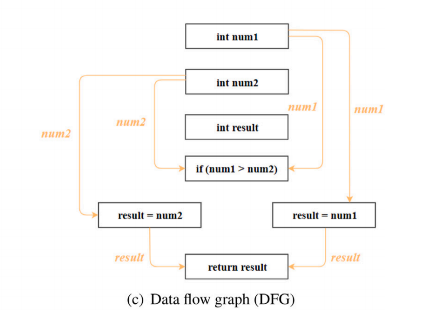
CCG(代码复合图)
BGNN4VD: Constructing Bidirectional Graph Neural-Network for Vulnerability Detection
以AST为主体,结合CFG和DFG的代码图,融合了控制依赖和数据依赖。
PDG(程序依赖图)
PDG描述代码之间的是如何相互影响的,程序依赖图包含了两种依赖关系,数据依赖和控制依赖。其中数据依赖关系描述了代码间存在变量的访问和修改,控制依赖关系描述了代码间存在控制传递,PDG也是一种复合图,融合了DDG和CDG。
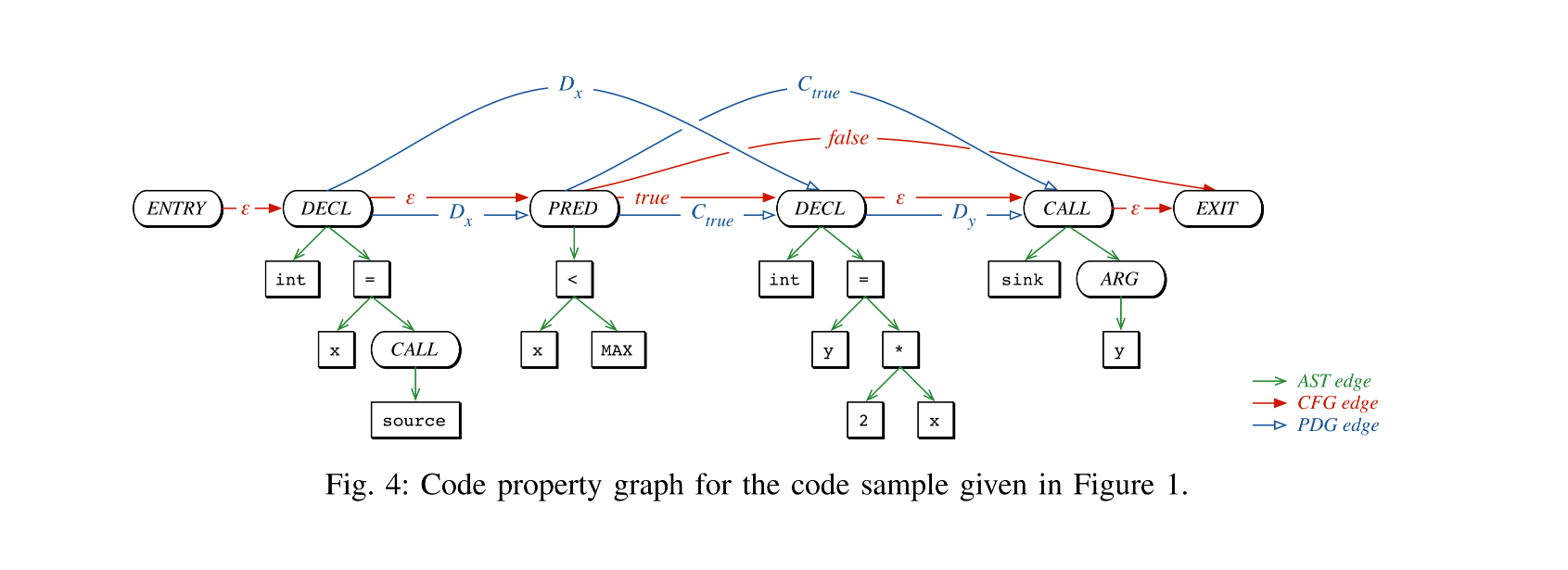
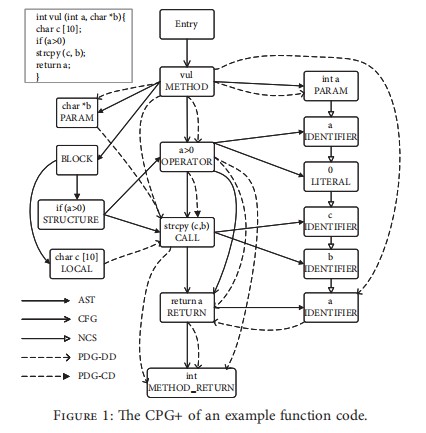
CPG(代码属性图)
Modeling and Discovering Vulnerabilities with Code Property Graphs
不同的图反映代码不同层面的语义信息,然而,在绝大多数情况下,仅凭单一表示不足以描述漏洞类型。代码属性图(CPG)将抽象语法树、控制流图和程序依赖图的特性结合在一个联合数据结构中,CPG可以集合了不同表示的优势。AST将源代码中的所有Token以及谓词都表示为一个节点,较CFG和PDG更进一步的细分,因此以AST为主体,将控制依赖和数据依赖融合在一起,构成代码属性图。
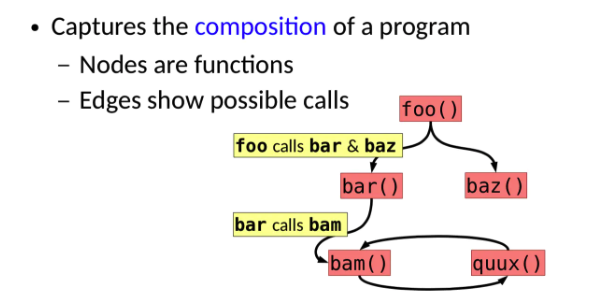
PCG(程序调用图)
程序调用图描述的是程序中函数的调用关系,节点代表函数,箭头代表函数间的调用关系。
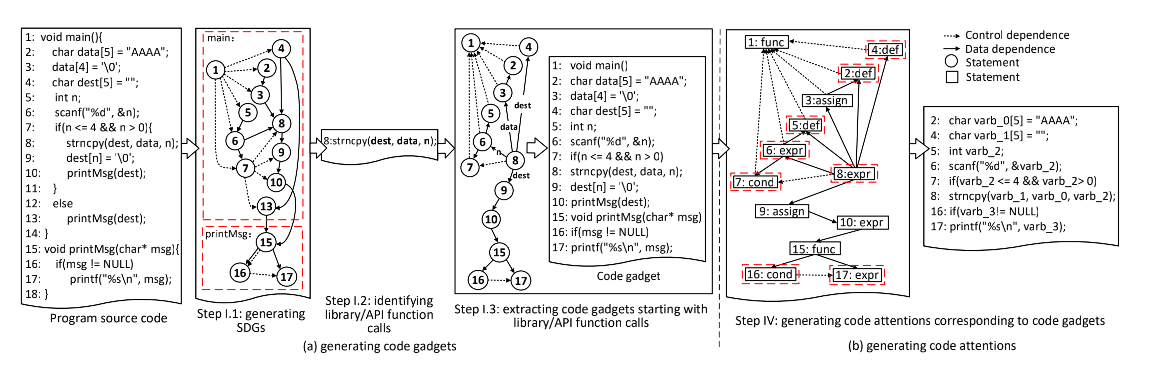
SDG(系统依赖图)
µVulDeePecker: A Deep Learning-Based System for Multiclass Vulnerability Detection
一个SDG是由一组程序依赖图(PDGs)推导出的,它表示数据依赖关系和控制依赖关系。PDG是一种有向图,其中节点表示语句或控制谓词,而有向边表示两个节点之间的数据或控制依赖关系。
首先生成源代码的SDG,然后定位到library/API,然后通过调用回溯找到相关的代码行,生成code gadgets。然后根据漏洞语法特性进一步提取相关的核心代码行。后续的操作和VulDeePecker一致。在提取核心代码行的时候采用三种语法特征:
- library/API函数调用中参数的定义语句,这将提供用于识别library/API函数调用使用不当的信息,区分数据源是否造成的漏洞。
- 控制语句:在执行目标library/API函数调用之前,是否进行了适当的边界检查和安全筛选。
- 包含library/API函数调用的语句,这将直接有助于识别漏洞类型。
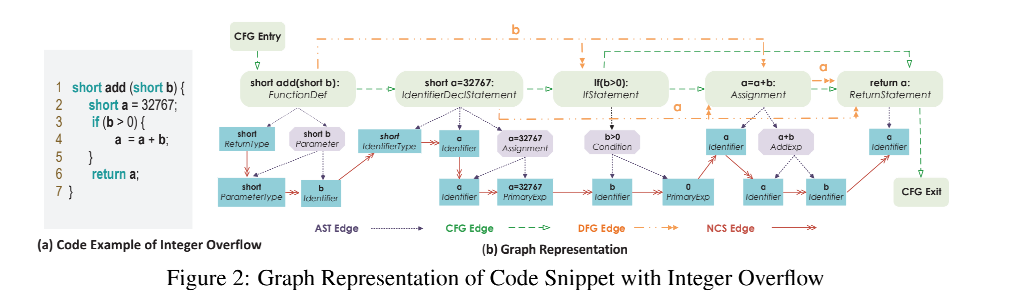
复合语义表示方法:AST + CFG + DFG + NCS
Devign: Effective Vulnerability Identification by Learning Comprehensive Program Semantics via Graph Neural Networks
该方法以AST为主干,显式地将不同级别的程序控制和数据依赖关系编码为一个异构边的联合图,每种类型都表示关于对应表示的连接。该方法可以捕获尽可能广泛的漏洞类型和模式,并能够通过图神经网络学习更好的节点表示。
AST(抽象语法树)
AST是源代码的有序树表示结构。通常,代码解析器使用它来理解程序的基本结构和检查语法错误的第一步表示。从根节点开始,代码被分为代码块、语句、声明、表达式等,最后进入形成叶节点的token。
CFG(控制流图)
描述了在执行过程中可能遍历的所有路径,在CFG中,节点表示语句和条件,它们通过有向边连接,以表示控制的传递。
DFG(数据流图)
跟踪整个CFG中变量的使用情况,数据流是面向变量的,任何数据流都涉及到对某些变量的访问或修改。
NCS(自然代码序列)
表示代码的整个自然表示序列,
例如:short -> add -> short -> b -> short -> a -> 32767,
为了编码源代码的自然顺序,使用NCS边缘来连接ASTs中的相邻代码tokens。这种编码的主要好处是保留由源代码序列所反映的编程逻辑。
复合语义表示方法:CPG+ = AST + CFG + NCS + PDG-DD + PDG-CD
HGVul: A Code Vulnerability Detection Method Based on Heterogeneous Source-Level Intermediate Representation
该方法以AST为主干,将代码的控制流图,数据依赖关系,控制依赖关系和代码自然序列融合而成的复合图
PDG-DD(PDG中的数据依赖)
本质上就是数据依赖图PDG-CD(PDG中的控制依赖)
本质上就是控制依赖图
总结
虽然源代码的表征方法是有很多种,但是都有一个目标就是尽可能多的保留更多的语义信息。在表征方法上,还是以AST,CFG,DFG,NCS(Token也可以看做是NCS)四种方法为主,其他的都是在这个上面做改进。现有的表征方法也存在一定的问题,比如说语义消解问题,以Python代码为例: a = 10; a = String(a); 很明显这里的a一个是int,一个是String,虽然二者的语义不同,但是在图中的表示确是一样的(都是节点a),因此语义消解也是需要解决的一大问题。