MVP: Detecting Vulnerabilities using Patch-Enhanced Vulnerability Signatures
来源信息
- USENIX Security Symposium(CCF A)
- 机构:中国科学院信息工程研究所
- 作者:Yang Xiao; Bihuan Chen; Chendong Yu; Zhengzi Xu et al.
摘要
反复出现的漏洞在现实世界的系统中广泛存在,而且仍然没有被检测到,而这些漏洞通常是由可重用的代码库或共享的代码逻辑造成的。然而,脆弱功能及其修补功能之间潜在的小差异,以及脆弱功能和目标功能之间可能存在的大差异,检测到的基于克隆和基于功能匹配的方法为识别这些反复出现的漏洞带来了挑战,即导致较高的假阳性和假阴性。
在论文中,作者提出了一种新方法以低假阳率和假阴率去检测重复发生的漏洞,首先使用程序切片来从语法和语义级别上的脆弱函数及其修补函数中提取漏洞和补丁签名。然后,如果目标函数与漏洞签名相匹配,但与补丁程序签名不匹配,则它将被识别为可能易受攻击。作者在MVP工具中测试该方法,对10个开源系统的评估表明,i)MVP显著优于最先进的基于克隆和基于函数匹配的漏洞检测方法;ii)MVP检测到了通用的漏洞检测方法无法检测到的反复漏洞; iii)MVP检测到了97个新漏洞,申请了23个CVE。
介绍
现有的方法
匹配反复出现漏洞的方法大致的思想是在目标的程序代码中匹配已知的漏洞代码,现有的方法主要分为两种:基于克隆方法,基于函数匹配方法。
- 基于克隆的方法
该方法将重复出现的漏洞检测问题视为代码克隆的检测问题,它们从已知漏洞中提取令牌或语法级签名,并识别签名的代码克隆可能容易受到攻击。 - 基于函数匹配的方法
直接将已知漏洞的中漏洞函数作为签名,并检测这些漏洞函数的克隆。
现有的挑战
- 第一个挑战是如何区分已经修补的漏洞,以减少误阳性。
- 第二个挑战是如何精确地生成一个已知漏洞的签名,以减少假阳性和假阴性。
论文方法
文章提出了针对反复出现的漏洞检测方法MVP(Matching Vulnerabilities with Patches)匹配漏洞以及补丁。具体来说:
- 为了解决第一个挑战,我们不仅生成一个漏洞签名,而且还生成一个补丁签名来捕获漏洞是如何导致和修复的。我们利用漏洞签名来搜索潜在的脆弱功能,并使用补丁签名来区分它们是否已经打过补丁。
- 为了解决第二个挑战,我们提出了一种新的切片方法,只提取与漏洞相关和补丁相关的语句,以在语法和语义级别上生成漏洞和补丁签名。
- 此外,我们还应用语句抽象和基于熵的语句选择来进一步提高MVP的准确性。
方法评价
MVP在10个具有25,377个安全补丁的开源系统上进行了评估。比较两种最先进的、最密切相关的基于克隆的方法(ReDeBug和VUUDY)。结果表明,MVP优于ReDeBug和VUUDY,其精度提高了74.5%和75.6%,召回率提高了42.4%和65.8%。MVP发现了97个新的漏洞,并成功提交了23个CVE。我们还将MVP与基于函数匹配的方法(SourcererCC and CCAligner)进行了比较。结果表明,MVP性能优于SourcererCC和CCCligner提高了83.1%和83.3%,召回率提高了22.5%和30.6%。
论文贡献
- 文章提出并实现了一种新的通过利用程序切片利用漏洞和补丁签名来实现重复漏洞检测的方法。
- 作者进行了密集的评估,以将MVP与四种最先进的方法进行了比较。MVP在准确性上明显优于他们。
- 在10个开源系统种进行测试,发现了97个新漏洞,提交了23个CVE。
动机
方法
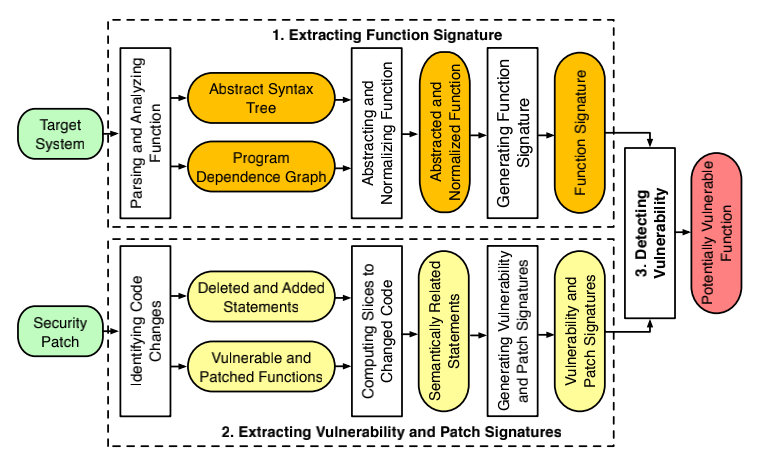
- 提取函数签名的步骤:以目标系统作为输入,并为目标系统中的每个函数生成一个签名。
- 提取漏洞和修补程序签名的步骤:将安全补丁程序作为输入,并生成漏洞签名和补丁程序签名,以从漏洞如何引起以及如何修复漏洞的角度反映漏洞。
- 最终的“检测漏洞”步骤:通过将目标系统中的每个函数与漏洞和补丁签名匹配来确定该功能是否存在潜在的脆弱性。
定义
- 函数签名:给定一个C/C++函数 f,我们将它的签名定义为一个元组(fsyn,fsem),其中fsyn是函数中所有语句的哈希值的集合;fsem是一组3元组(h1,h2,type),这样h1和h2表示两个语句的哈希值,type{data,control}表示哈希值为h1的语句对其哈希的语句具有数据或控制依赖性.
fsyn捕获目标函数的语句作为语法签名。fsem捕获数据,并控制函数中语句之间的依赖关系作为语义签名。这提供了一个函数的补充信息,以帮助提高匹配的精度.
在本文的其余部分中,我们假设每个漏洞都在一个函数内。我们使用(fv,pv)来表示一对脆弱的函数fv和其补丁函数pv。
- 函数补丁:给定一对函数(fv、pv),函数补丁Pv由一个或多个hunk(块)组成。hunk是补丁中的一个基本单元,它由上下文行、已删除的代码行和/或已添加的代码行组成。被删除的行是fv中,但在pv中缺少的行。而添加的行是在fv中缺少但在pv中存在的行。
提取函数签名
解析和分析函数
给定目标系统的源代码作为输入,首先使用Joern来解析代码并生成一个代码属性图,它将抽象语法树、控制流图和程序依赖图合并为一个联合的数据结构。从代码属性图中,首先得到目标系统中的所有函数,然后对每个函数生成其抽象语法树(AST)和程序依赖性图(PDG)。
抽象化和规范化的函数
由于开发人员可以重用具有重命名参数/变量的代码片段,因此首先在提取签名之前对每个函数执行抽象,以避免假阴。具体地说,从一个函数的AST中识别形式参数、局部变量和字符串文本,并替换所有的形式参数、局部参数和字符串文本。
- 形参 -> PARAM
- 局部变量 -> VARIABLE
- 字符串 -> STRING
在抽象之后,通过删除所有注释、大括号、tabs和空白,对函数体中的每个语句应用规范化。
函数签名生成
为了生成函数签名,我们首先对每个抽象和规范化的语句应用一个哈希函数来计算一个hash值。因此,函数的语法签名fsyn被表示为语句的计算哈希值的集合。
然后,我们从一个函数的PDG中提取数据或控制两个语句之间的依赖关系,每个依赖项表示为3元组(h1、h2、type)。一个函数的语义特征,表示为fsem,因此被表示为一组提取的依赖项。我们的抽象和规范化可能会丢失一些信息,并导致假阳性,但是考虑到语义信息(即语句之间的控制或数据依赖性)可以弥补抽象和归一化的不足。

提取漏洞及补丁签名
识别代码修改
我们首先通过解析安全补丁的头(即diff文件)来识别更改的文件,并记录获得更改文件的易受攻击和补丁版本的提交。为了识别更改的函数,我们通过解析diff文件来查找已删除和添加的语句及其行号。并在更改的文件的易受攻击版本和补丁的版本中获取所有函数以及它们的开始和结束行号。如果一个语句包括一个或多个已被删除的代码行,我们认为该语句已被删除(或添加)。部分修改的语句是删除语句、添加语句或删除语句和添加语句。
通过检查已删除的(或添加的)语句的行号是否在已更改的文件的脆弱的(或补丁的)版本中函数的开始和结束行号的范围内,我们确定所有更改的函数,针对每一个函数,我们还提取Sdel和Sadd、Svul和Spat。
利用切片技术可以提取相关的语句和排除不相关的语句。作者在PDG上执行前后切片,使用已删除的语句Sdel(Sadd添加的语句)作为切片的标准。向前向后切片是根据函数的依赖关系,包括数据依赖和控制依赖。
传统的程序切片存在的问题:
- 如果说将条件语句设置为切片准则,正向切片的结果可能包含太多的语句,其中会包含一些与漏洞无关的噪声语句。如图可以发现 24行与18行和23行相关,但是却与28行(漏洞行)无关。
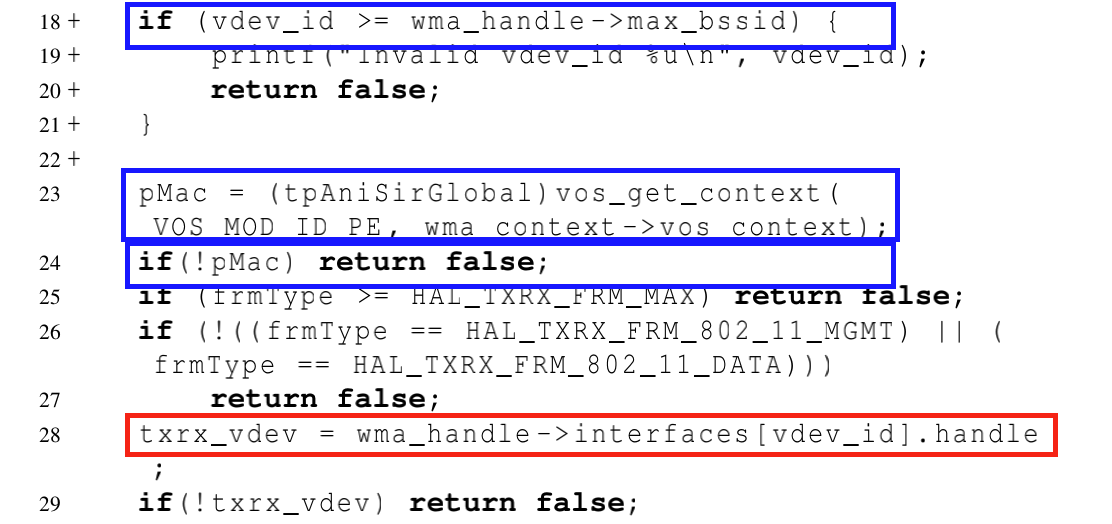
- 一个补丁可以只是添加一个函数调用(第3行),而不使用其返回值。因此,如果将函数调用语句设置为切片标准,我们只有向后切片结果,但没有得到正向切片结果。

前两种程序切片方法都存在问题,所以作者提出了一种新的切片方法。作者将Sdel和Sadd中的每个语句作为切片的标准。
反向切片:对Fv和Pv的PDG进行正常的向后切片,获取对数据和控制依赖关系有影响的切片标准的所有语句。
前向切片:对Fv和Pv的PDG进行前向切片时,根据不同的语句类型执行不同的切片准则。
- 赋值语句:进行正常的正向切片,按照数据流进行常规切片即可
- 条件语句:在正向切片的过程中只针对条件语句中使用的的变量或参数进行切片。
- 返回语句:返回值与返回语句之后的语句之间如果不存在任何依赖关系了则不需要向前切片。
- 其他:其他类型包括未使用返回值的函数调用语句。与条件语句类似
漏洞和补丁签名生成
漏洞签名可以用于查找潜在的漏洞函数,补丁签名可以区分它们是否已经被修补。在语法和语义级别上计算漏洞签名(即Vsyn和Vsem)和补丁签名(如Psyn和Psem)。
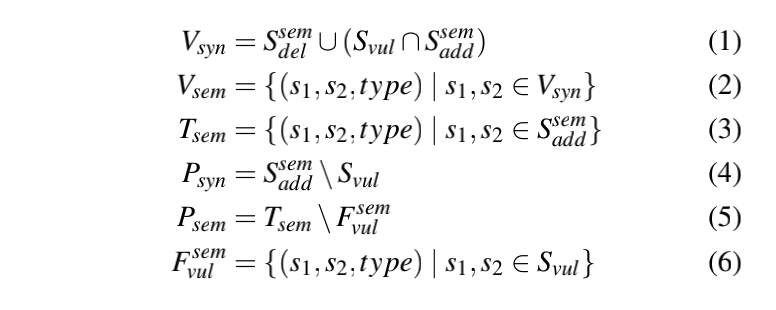
我们用等式来计算Vsyn.S(sem)del是与删除语句相关的语句,因此它与漏洞的原因直接相关.S(sem)del可能不会包含所有的漏洞语句。
通过匹配来检测漏洞
给定目标系统中每个函数的函数特征(fsyn;fsem),以及删除的语句Sdel、漏洞特征Vsyn和Vsem,以及补丁中每个已更改函数的Psyn和Psem,根据以下原则判断目标系统中的某个函数是否具有潜在的脆弱性签名与漏洞签名匹配,但与修补程序签名不匹配。具体地说,如果目标函数满足以下五个条件,即C1到C5,则它可能是易受攻击的。

- C1:目标函数必须包含所有已删除的语句
- C2:目标函数的签名与漏洞签名在语法层次(syn)上匹配
- C3:目标函数的签名与补丁签名在语法层次(syn)上不匹配
- C4:目标函数的签名与漏洞签名在语义层次(sem)上匹配
- C5:目标函数的签名与补丁签名在语义层次(sem)上不匹配
具体阈值可以由用户配置
评估
实验回答以下五个问题:
- Q1:与最先进的方法相比,MVP在检测反复出现的漏洞方面的准确性如何?
- Q2:与最先进的方法相比,MVP在检测重复出现的漏洞方面的可扩展性如何?
- Q3:在MVP的匹配过程中,如何配置阈值?
- Q4:语句抽象和语句信息如何采样才能有助于MVP的准确性?
- Q5:通用漏洞检测方法检测重复漏洞的性能如何?
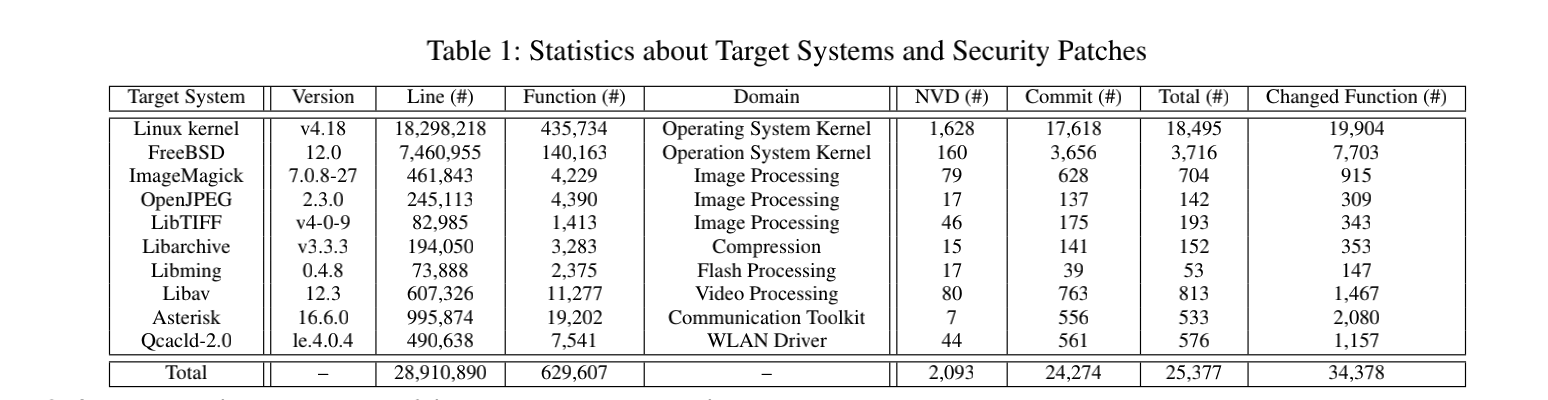
数据集
开源的C/C++项目
试验结果
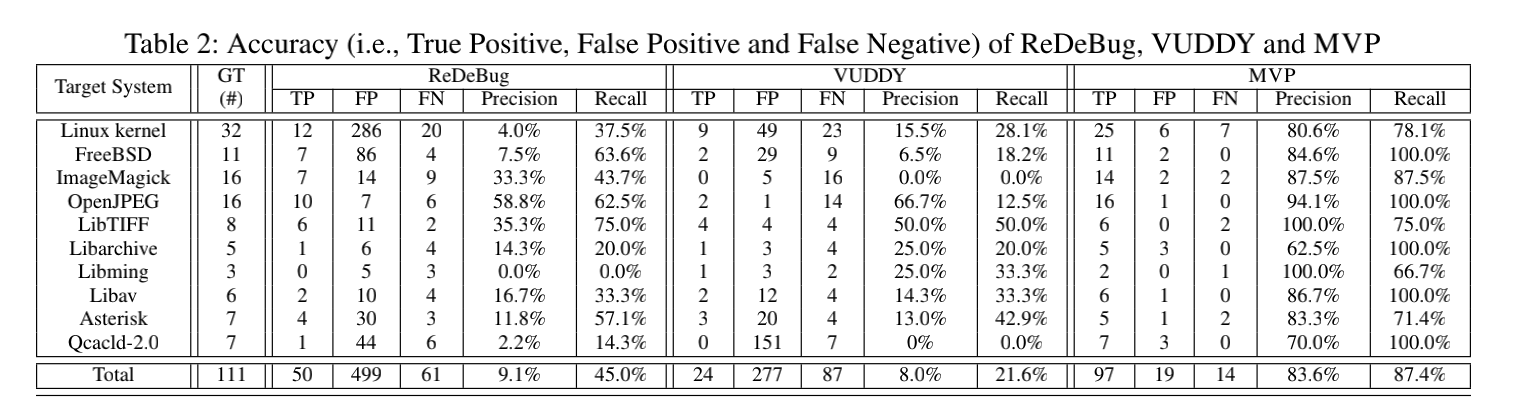
Q1:与最先进的方法相比,MVP在检测反复出现的漏洞方面的准确性如何?
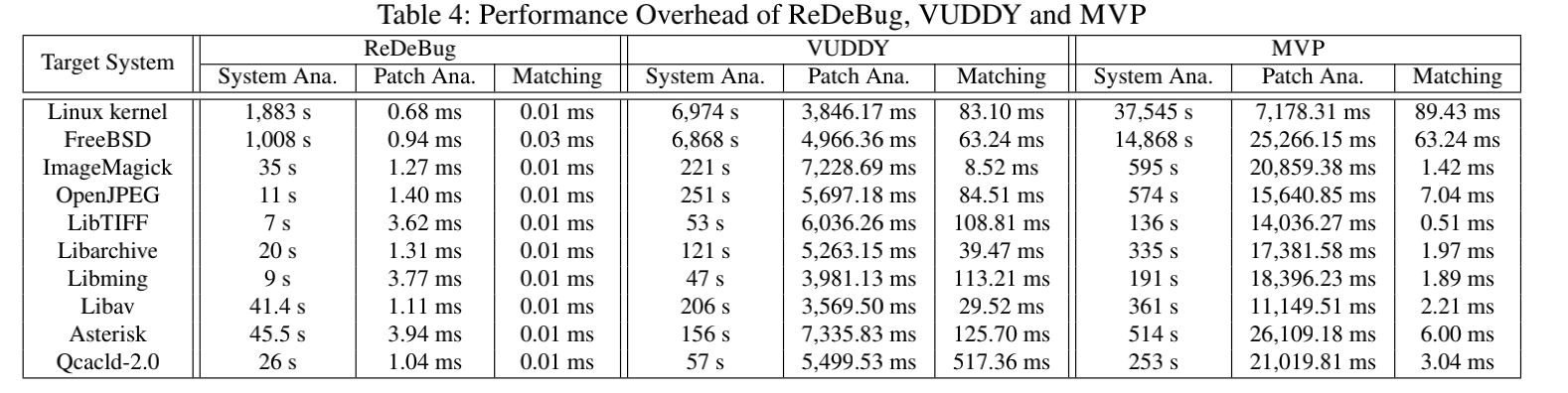
Q2:与最先进的方法相比,MVP在检测重复出现的漏洞方面的可扩展性如何?
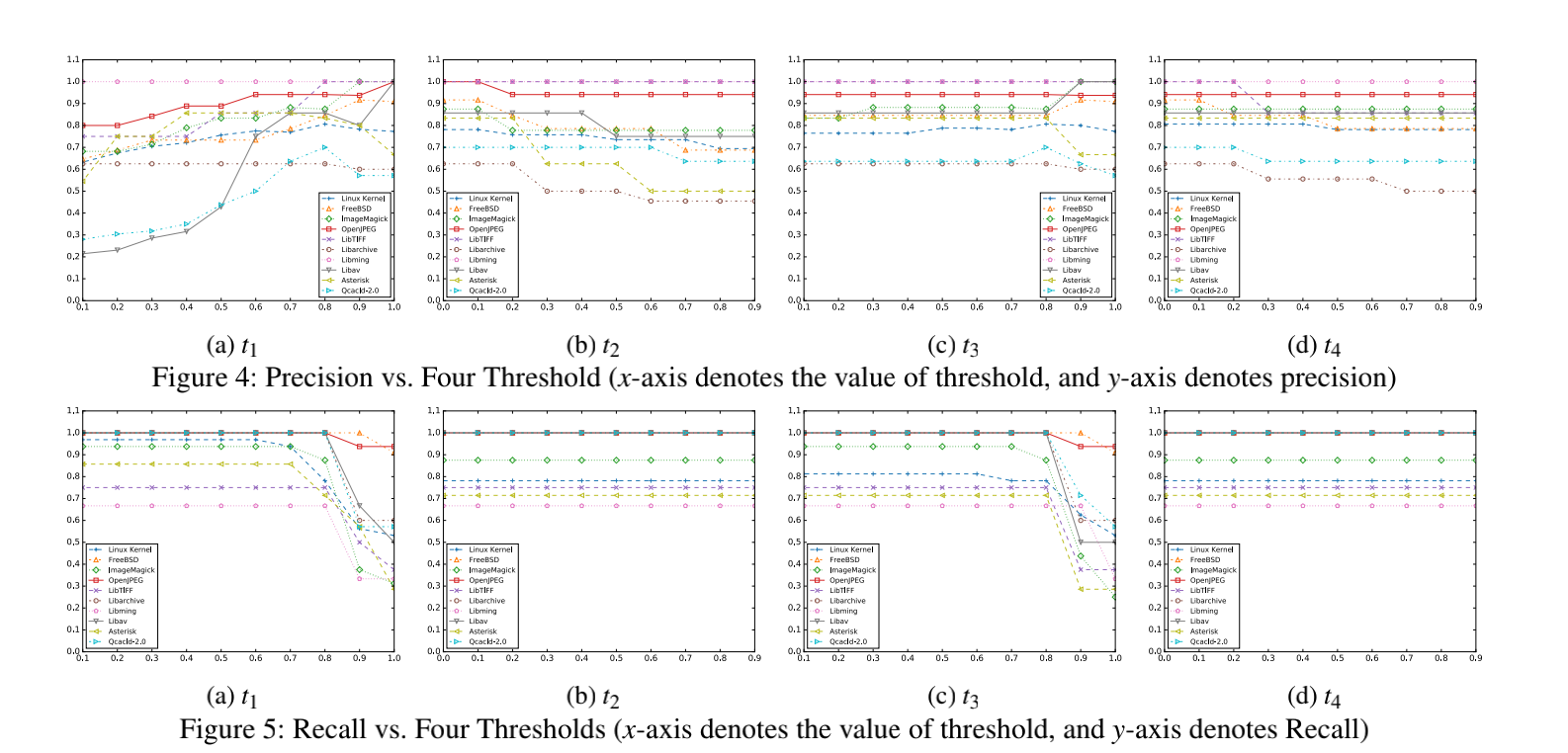
Q3:在MVP的匹配过程中,如何配置阈值?
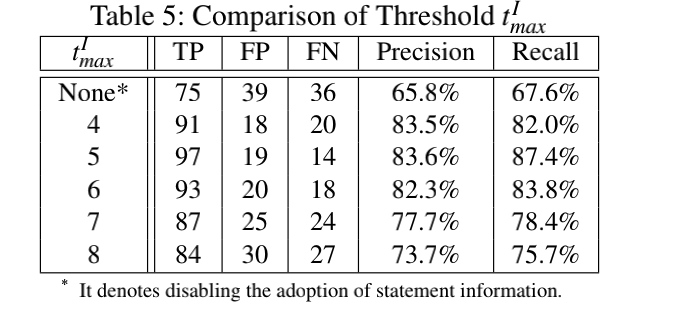
Q4:语句抽象和语句信息如何采样才能有助于MVP的准确性?
Q5:通用漏洞检测方法检测重复漏洞的性能如何?
对比了VulDeePecker、Devign、Coverity、Checkmarx。MVP的方法检测效果要高于这四种方法。
总结
局限性
- MVP只专注于检测反复出现的克隆漏洞
- 使用joern生成代码的属性图,只适用于C/C++
- 通过宏来修复的漏洞代码无法进行检测
- 只对形式参数、局部变量和字符串进行抽象,因此无法发现已知漏洞函数具有类似函数调用或数据类型的潜在脆弱函数