SeqTrans: Automatic Vulnerability Fix via Sequence to Sequence Learning
来源信息
- 机构:西安交通大学, UC Riverside
- 作者:Jianlei Chi, Yu Qu, Ting Liu, Member IEEE, Qinghua Zheng, Member IEEE, Heng Yin, Member IEEE
- 期刊:Arxiv
摘要
论文提出了一种自动化的源代码漏洞修复方法 SeqTrans。为了捕获漏洞代码的上下文信息,论文利用数据流依赖性来构建代码序列并将其输入到Transformer模型中。同时引入了注意力机制更好的学习漏洞和补丁之间的差异。在包含 1,282 次提交的数据集上评估了SeqTrans在单行和多行漏洞修复的效果。结果表明,SeqTrans 的准确率在单行修复中可以达到77.6%,在多行修复任务中可以达到52.5%的准确率。同时发现NMT(神经机器翻译) 模型在某些类型的漏洞中表现非常好,例如 CWE-287(不正确的身份验证)和 CWE-863(不正确的授权)。
方法
为了更好的捕获脆弱代码周围上下文信息,论文利用数据流依赖关系来构建代码序列,将其输入到transformer模型中,并引入微调策略来克服漏洞数据集不足的问题。
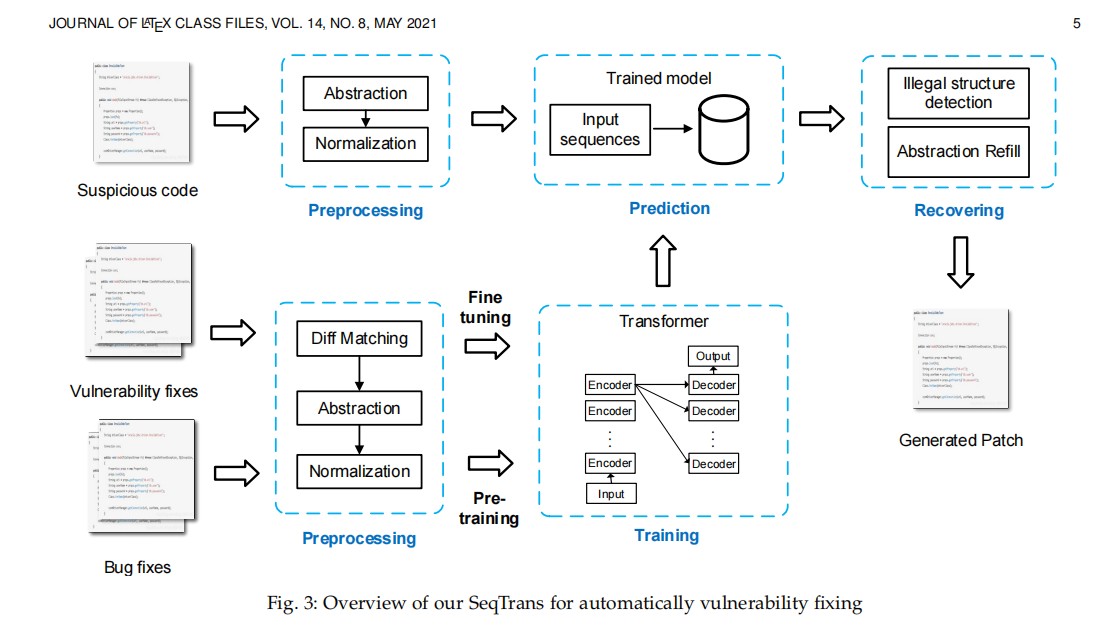
整个模型包括三个模块:预处理模块,预训练和微调,预测和补丁
- 预处理模块:从补丁和漏洞文件中提取diff上下文,然后进行规范化并提取数据依赖,利用def-use链可以捕获漏洞周围的语法和结构信息并减少噪声的引入,适用于transformer模型
- 预训练和微调模型:bug修复和漏洞修复有一些共通之处,bug领域的数据集较多而漏洞领域的数据较少,为此论文从一般任务域数据集(bug修复数据集)中学习和捕获部分一般特征和超参数。经过预训练之后,再在漏洞修复数据集上对transformer模型进行微调,以适用于漏洞修复任务。
- 预测和补丁:输入一个漏洞文件,SeqTrans可以为用户提供多个候选项来选择最合适的预测。
选择数据流依赖的原因:(1)围绕脆弱语句的上下文对于理解风险行为和捕获结构关系是有价值的(2)数据流依赖关系为转化提供了足够的上下文(3)控制流依赖关系通常包含分支,这使得它们太长,无法进行标记化。
def-use链意味着为一个变量赋值一些值,其中包含脆弱语句中的所有变量定义
预训练
漏洞修复可以看作是漏洞修复的一个子集,因此利用bug修复的数据集进行预训练。我们相信,通过对通用数据进行预训练,我们可以学习到许多可应用于漏洞修复任务的通用修复经验和特性。
微调
微调的目的是在目标数据集比源数据集小得多时,提高模型的泛化能力。使用这种方法,我们可以结合两个相关的工作:漏洞修复和bug修复。利用新的漏洞修复语料库对上一个训练过程中训练的模型进行微调,以便将bug修复训练中学习到的知识转移到漏洞修复任务中。
Encoder
该编码器由6个相同的层组成。每一层由两层子组成:多头自注意机制和前馈神经网络。每个子层都采用了残余连接和归一化,这样我们就可以将子层的输出表示为:
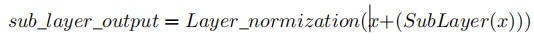
其中,Sublayer(x)是由子层本身实现的函数。自我注意机制从前一个编码器中接收到一组输入编码,并相互权衡它们之间的相关性,以生成一组输出编码,前馈神经网络分别处理每个输出编码。这些输出编码最终作为其输入传递给下一个编码器。
Decoder
解码器堆叠6个相同的层。但是,每一层由三个子层组成:增加了一个注意子层来执行多头注意,从编码器生成的编码中提取相关信息,其他部分与Encoder一致。
Attention Mechanism
注意机制的目的是使用一组编码来将上下文合并到一个序列中。文章使用的是通用的self-attention机制
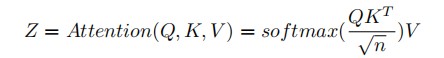
预测和补丁生成
Decoder原始的输出是抽象和规范化的语句,同时可能存在一些语法错误,文章补丁生成提出两个步骤解决:抽象重新填充和语法检测。
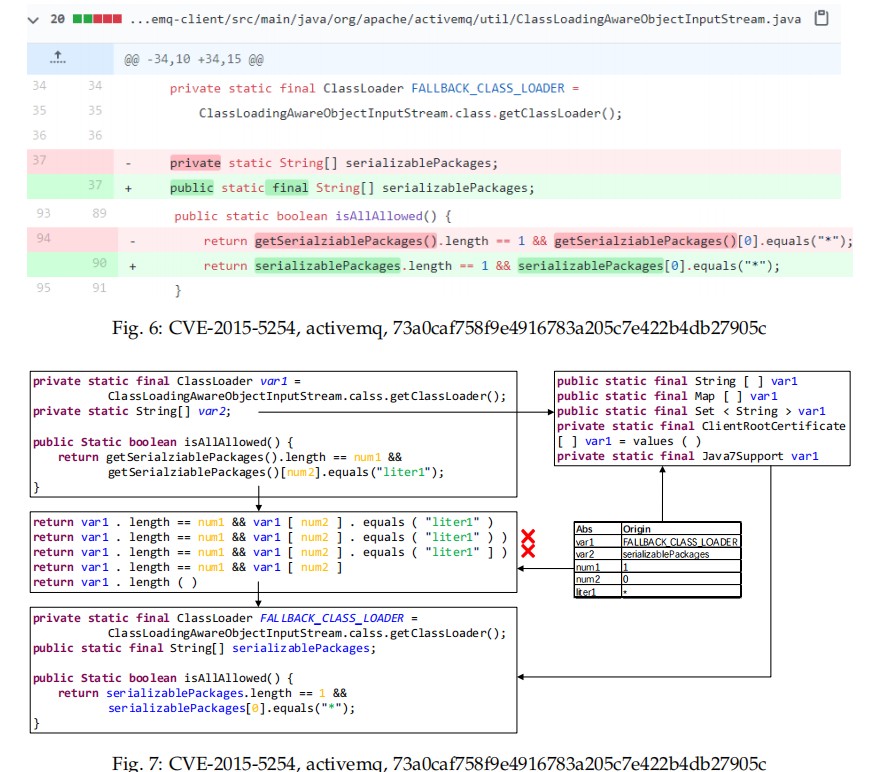
如图所示,每个脆弱的语句将生成5个候选预测语句。通常,我们会被选择和利用排名最高的预测。在某些情况下,预测结果中存在语法错误。我们将使用语法检查工具来检测这些错误。在整个预测过程中,维持一个字典来保存CP的相关变量,常量,字符串的映射关系。方便后续将预测的补丁还原。利用FindBugs来检查预测补丁中的语法问题。