PBCNN: Packet Bytes-based Convolutional Neural Network for Network Intrusion Detection
来源信息
- Computer Networks(CCF B)
- 机构:清华大学
- 作者:Lian Yu; Jingtao Dong; Lihao Chen; Mengyuan Li; Bingfeng Xu et al.
摘要
网络入侵检测系统(IDS)可保护目标网络免受数据泄露和人员隐私不安全的威胁。然而,现有的网络入侵检测研究大多不能有效地实现对目标的保护,特别是在很大程度上取决于利用领域专家的知识和经验人工设计的统计特性,并且未能解决少数样本数据问题。网络流量具有层次结构,即字节数据包流。本文提出了
一种基于字节的分层包CNN,称为PBCNN,第一级自动从原始Pcap文件中的字节中提取抽象特征,然后第二级进一步构建流或会话中的包表示,而不是使用已有的CSV文件中的特征,充分利用原始数据信息。多个卷积池模块与大小可变的卷积核级联,一层TextCNN获得流量流的表示,并将表示到3层全连接网络进行入侵分类。应用基于PBCNN的小样本学习,提高了少实例问题的网络攻击类别的检测可靠性。实验表明,CIC-IDS2017和CSE-CIC-IC-IDS2018数据集优于现有的研究。
介绍
现有的问题
使用过时的数据集
63.8%的人使用了KDDCUP99数据集,这些数据集可能不包含当前互联网中网络入侵的某些特征。因此,所提出的方法可能不能很好地检测到当前的网络入侵。
使用传统的学习方法
利用传统的机器学习方法,如SVM(支持向量机)和决策树(DT)来检测网络入侵。
依赖于人工或半人工获得的统计特征
CIC-IDS2017和CSE-CIC-IDS2018数据集相对较新,具有更多的网络攻击类型。但是现有的研究9篇有8篇是基于CSV格式的数据集进行检测的,它们的研究高度依赖于提取的特征,而不是原始的网络流量数据,即CSV文件中统计特征的质量成为这些研究的上界。
未能解决少数样本数据问题
实际上,尽管互联网上有大量的网络流量数据,但攻击流量数据的量非常小,而且这些数据往往难以标记。因此,异常类别或类的训练样本往往不足,而且大多数现有的检测方法可能很难检测到这类类型的攻击。
论文的贡献
提出了一种特征提取和分类模型:为了从原始流量数据中自动提取抽象特征并增强评价指标,提出了一种基于字节的分层卷积神经网络(PBCNN),以适应网络数据流的层次,自动从包中的字节中提取抽象特征,并从会话或流中的分组中提取抽象特征,并进一步执行网络入侵检测的多种分类。实验表明,该模型优于使用CIC-IDS2017和CSECIC-IDS2018数据集的最新模型。
处理小样本:为了提高网络攻击类别的检测能力,本文提出了一种基于PBCNN的小样本学习,利用数据集CIC-IDC2017和CSE-CIC-IDS2018来检测异常网络流量,并与其他2D-CNN模型进行比较,证明了小样本能力的影响。
利用一个相对较新的数据集:本文利用了CIC-IDS2017年生成的CSE-IIC-CIC-IDS2017年和2018年生成的数据集,分别包含12种和14种网络攻击。根据官方网站的介绍,数据集是通过模拟当前互联网中的网络流量分布生成的,包含大量的原始流量,特别是CSE-CIC-IDS2018高达470GB。因此,它们相对更适合于网络入侵检测的研究。
网络流量数据预处理
分析网络流量
每一个pcap文件都是如下的结构,在解析的过程中就按照该结构进行分层解析。

在Pcap头之后,有许多捕获的包,每个包包括包头和包数据。以数据包的TCP/IP协议格式为例,开发的解析器根据需要根据协议提取每个字段。

组织网络流量
网络流量粒度对数据格式和数据分布方面的分析有影响。本文探讨了基于双流的检测方法,也称为会话,其中源IP地址-源端口、目标IP地址-目标端口可以成对交换。从网络数据包中提取五个数据(源IP地址-源端口、目的地IP地址-目的地端口、协议),并将进一步的数据包组织成会话。当五元中的任何元素丢失时,数据包将不参与建模和分析。
在对网络流进行解析,得到时间戳和五元组信息后,按五元组信息进行分组,得到根据设计的分割策略进行分割的会话数据,得到会话样本。

上面获得的会话可能包含大量的数据包。需要一种分割策略来分离会话数据,以便进一步进行建模和分析。会话分割策略:
- 使用TCP连接的相关标志来确定会话的开始和结束:例如,可以使用“三方握手”中的SYN作为开始标记,也可以使用“四手波”中的FIN作为结束标记,来分割一个会话。
- 对会话数据使用超时策略:当通信链路等待很长时间,即空闲时间-无数据包交互,超过预设阈值时,认为会话终止。
- 使用周期重置策略:如果通信链路上的信息交互时间超过预设阈值,则会话被迫截断,随后的数据包合并为新的会话。
本文采用的分割策略为超时策略(64s)和周期重置策略(120s)。
整个分割过程如下:

如图所示,它首先从会话数据中读取数据包,并将数据包的时间戳信息与前数据包的时间戳信息进行比较。如果时间间隔时间不超过64秒,则它将继续与会话的第一个数据包的时间戳进行比较。如果间隔时间不超过120秒,则该数据包将包含在会话样本中。否则,只要不满足上述两个条件中的任何一个,就将分组分成新的会话样本,存储旧的会话样本,同时记录分组的时间戳信息,然后处理下一个分组,直到会话数据中的所有分组都被处理。
数据转换
转换的目的是将会话数据处理为深度学习模型所接受的输入格式。此步骤包括匿名化、数字编码,以及统一会话示例中的字节和数据包的数量。
匿名化:网络流量数据中的地址,包括MAC源和目标地址,以及IP源和目标地址。
数字编码:将数据包转换为每字节0-255的像素值作为模型输入。

为了优化梯度更新方向并加快训练,根据最大值和最小值对数据进行归一化。
标签编码:使用one-hot编码方式。
网络入侵检测建模
选择该网络结构的原因
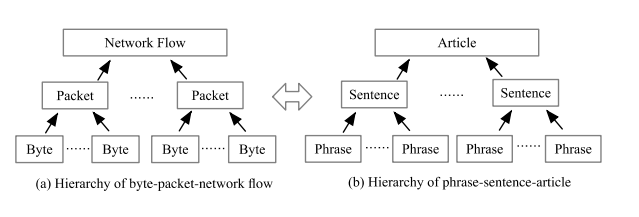
选择模型和确定神经网络结构的基础主要从两个方面来考虑:第一是数据处理、格式和特征;二是分类的性能和训练的效率。网络流在字节分组会话方面,具有分层结构,即,数据包由字节组成,而网络流或会话由数据包组成。它类似于自然语言处理(NLP)领域中的短语-句-文章的文本层次结构。CNN擅长捕捉局部上下文关系,如果多个卷积内核模块被级联以扩展接受域,CNN在获取远程信息依赖方面具有更大的潜力。一般来说,当有人认为某些信息属于上下文时,人们就会尝试使用CNN。此外,与RNN相比,CNN非常适合相似性,在GPU的加速方面具有显著的时间性能优势。
PBCNN模型结构:
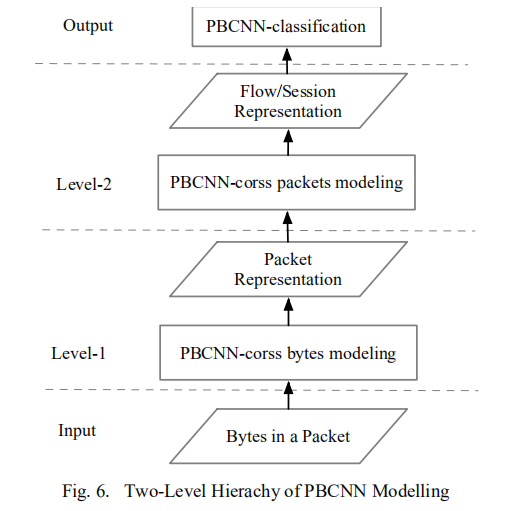
Input:数据包中的字节
Level-1:对字节进行建模,进行包的表示
Level-2:对包进行建模,流/会话表示
Output:输出分类的结果
由于会话中的数据包数量相对较小,就像处理TextCNN中NLP中的短语一样,不需要使用堆叠结构来扩展接受字段作为数据包中的处理字节。因此,只使用一层包含多个不同大小滤波器的卷积池模块从包向量学习表示来构建网络流,可以提高处理能力。
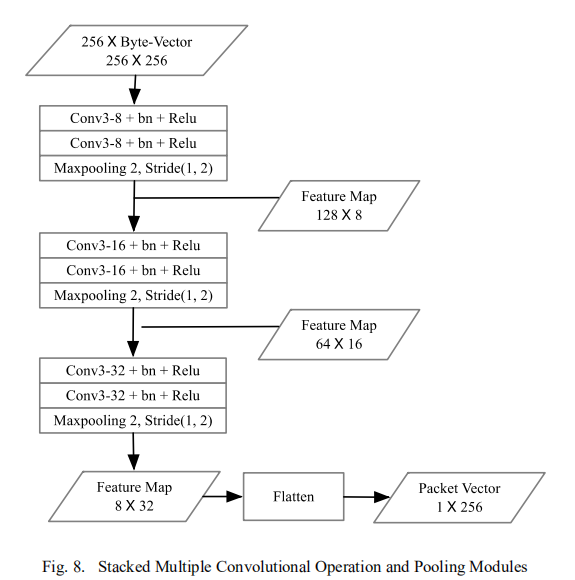
如下图为CNN模块:

小样本入侵检测
使用的方法:孪生网络。
来自同一类别的数据对的两个样本是标签为1的正样本;来自不同类别的两个样本是标签为0的负样本,正负样本比为1:1.5。在训练阶段,它将多分类任务转换为二元分类匹配任务。
孪生网络的底层使用PBCNN来提取网络流量的特征,网络的上层使用一个小的神经网络来学习两个样本之间的距离。由PBCNN提取的两个样本的表示。暹罗网络上层的输入包括两个样本,以及另外两个可以在一定程度上表示样本距离的特征。这两个特征是欧几里得距离和余弦相似性。
实验
CSE-CIC-IDS2018数据集按比例分为训练集、验证集和测试集,训练集用于训练模型,验证集选择参数,测试集用于模型的效果测试。本文对各类数据分层进行采样。根据6:1:3的比例,确保每种样本的比例一致,防止该类别中缺少一类数据。
- 分层实验对比
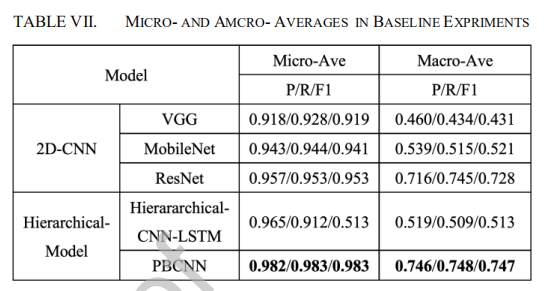
- 针对每一个类别的检测精度

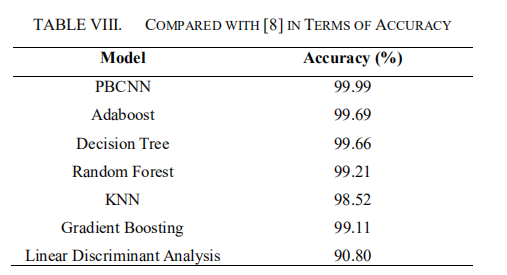
- 与其他算法的精确度对比
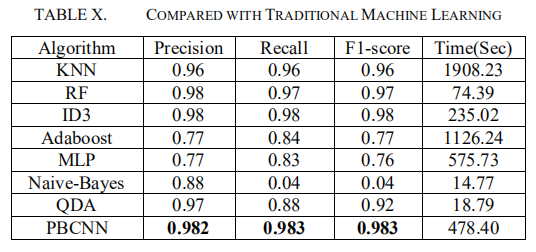
- 与传统机器学习算法对比
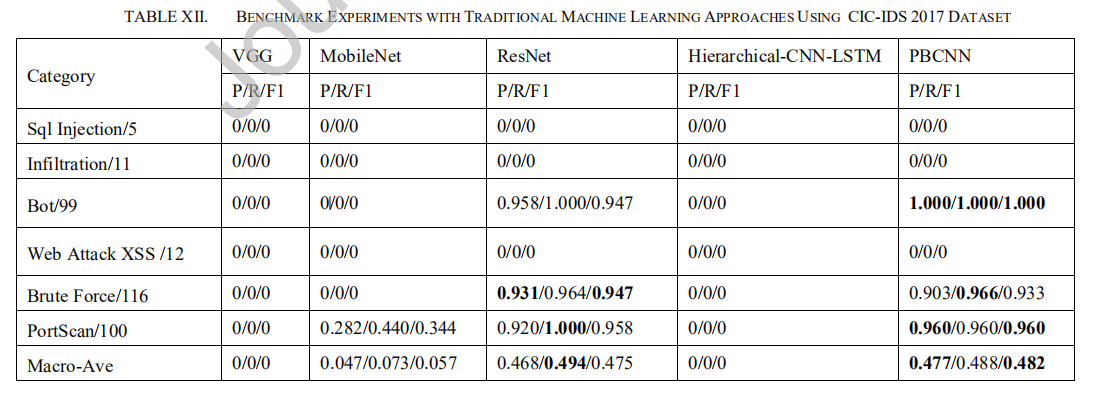
- 在CIC IDS2017数据集上的实验
总结
优势
- 使用分层的CNN来重新提取特征,相比直接使用CSV的现有特征,
- 应用小样本检测算法,可以提高检测未知类的精度。
思考
数据转换中,既然IP和Mac地址都转换成了0.0.0.0和00.00.00.00.00.00。已经没有了任何的信息,为何不选择直接进行移除,直接删除该字段可以减少数据包的长度,缩短token的长度。
在数据转化过程中,按照每个字节转化成0-255的像素值的话,有的字段是4个字节或者2个字节,按照单个字节转换的话,就会丧失该字段的语义信息。