SQVDT: A Scalable Quantitative Vulnerability Detection Technique for Source Code Security Assessment
来源信息
- 机构:清华大学软件学院信息系统安全重点实验室
- 作者:Junaid Akram,Ping Luo
摘要
在论文中,作者提出了一种漏洞检测技术来检测软件以及源代码级共享库中的漏洞,根据不同Web源的CVE编号跟踪和定位补丁文件,从而抓取脆弱源代码,并构建了2931个脆弱文件的指纹索引。之后,作者开发了一个基于代码克隆检测技术的漏洞检测方法,并在数千个Github开源项目中检测了数百个未被发现的漏洞,在最新版本的Linux、HTC内核、FindX中也有检测到漏洞。此外,作者还对这些漏洞进行了实证评估和验证,包括项目内克隆漏洞、复制内核克隆漏洞和库使用的克隆漏洞。该技术非常快速、高效、可靠、实用、可伸缩,可以在工业层面上实现。与最先进的工具的比较显示了该方法的有效性。
动机
以下原因促使在源代码级别上检测不同项目中的漏洞。
- OSS普遍使用的增加,增加了主要由代码克隆引起的软件漏洞,造成了巨大的威胁。
- 安全审计人员很难在大规模上审计漏洞检测的源代码。
- 大多数软件,直接或间接地依赖于外部组件,包括库,实用程序,和程序,这些可能是错误的或脆弱的。如此大量的组件重用是潜在的面向风险的。分析显示,近0.62%的Maven项目存在漏洞。
- 然而,大多数研究人员一直在研究基于模型的漏洞检测,这一重点是通过预测软件相关属性来预防软件漏洞。在源代码级别上,关注可扩展的定量漏洞检测的研究非常少。
- 重点关注基于其CVE号的脆弱源代码的检测。
- 通过关注精确匹配检测(脆弱代码)来降低错误检测率。
论文贡献
- 通过跟踪补丁文件来提取和构建漏洞源代码基准测试。
- 开发了一种基于代码克隆检测技术的漏洞检测方法(SQVDT)。
- 检测到一些非常著名的OSS中的漏洞。
- 对这些检测到的漏洞进行实证评估和验证研究。
- 基于补丁的静态分析对这些漏洞的影响。
- 展示了 7 TB 源代码(152,823 个项目)中许多检测到的漏洞的结果。
方法
代码克隆一共有四种类型:精确克隆、重命名克隆、重构克隆、语义克隆。

源代码预处理
首先跟踪补丁文件的原始源代码文件(打补丁之前的代码),来提取脆弱代码。删除所有的不相关代码,包括注释、空格等。然后将源代码转化成特定的token。在这过程使用词法分析器进行token化,同时为每一个token分配id。
替换规则:
- 替换标识符 -> idN,N表示出现的编号
- 替换字符串 -> null,替换所有的统一字符串为空
- 整数数值 -> 0
- 浮点型 -> 0
- 布尔型 -> true
例 : x = a + yz -> id0 = id1 + id2id3
提取代码特征
代码特征就是指纹,通过提取指纹,可以减少比较的代码量。特征包含以下五点:
- MD5哈希:对每个文件的前15个token和后15个token分别生成hash值,然后通过$进行拼接。hash(Pre 15)@hash(Suf 15)
- FNV哈希:指纹索引特征,将每个文件的总token分成10个相等的部分,即p0、p1、p2、…p9。然后对每个部分应用FNV hash来生成FNV哈希值。在生成FNV散列后,从每个文件的每个分区中选择10个最小的散列。然后将它们全部添加到一个单一的值(长整数)中,以形成另一个特性,它显示了每个文件的完整特性。
指纹索引
指纹索引的目的是用来快速寻找单个文件或者整个系统脆弱代码,所有的指纹索引使用HBase大表进行存储,该方法较为灵活快速。索引信息包括:MD5哈希值、易受攻击文件的路径、FNV哈希值和存储在HBase中的每个源文件的总令牌大小。指纹索引信息的示例如图所示。

漏洞检测
通过在项目上应用不同的过滤器来提取所有相关特征(MD5哈希、FNV散列、最小哈希和文件路径),过滤器将项目的相关特征与指纹的索引值进行比较。当系统和指纹数据集的特征100%相似时,就表示存在漏洞,并进行定位和展示。
- Filter 1:用来比较MD5哈希值,如果一致则进入下一个Filter。
- Filter 2:检测每个文件中的token总数,然后将它们与HBase中存储的指纹索引(单位)进行比较。
- Filter 3:用来比较FNV哈希值,如果一致则进入下一个Filter。
- Filter 4:在获得每个过滤器上的abstract克隆文件后,我们通过使用最小哈希进一步评估精确克隆的结果。最小哈希算法帮助我们进一步比较生成的文件,以找到精确的克隆文件。
- Filter 5:用来比较MD5哈希值,如果一致则进入下一个Filter。
实验
与SOAT进行对比的结果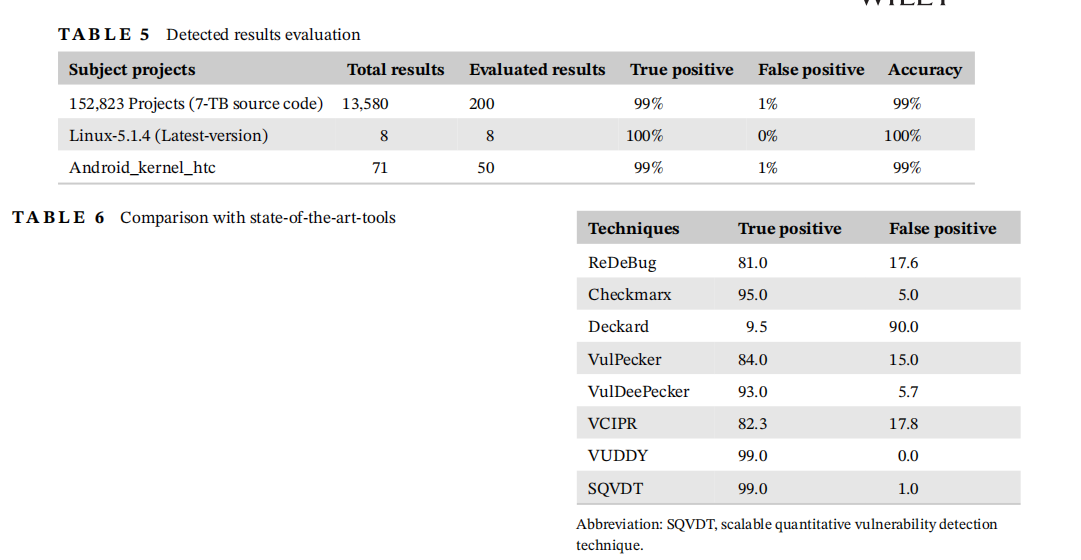
检测到的小米内核中的漏洞
思考
- 该方法不仅可以针对大规模的漏洞检测而且单个文件也可以进行检测。利用Hadoop可以实现分分布式的检索,提高检测的效率。
- 在图上可以看到,在Patch File -> Retrieved Vulnerable Code -> Preprecessing 这个过程中,提取到的脆弱代码就是补丁文件中删除的代码,这些代码语义信息并不完整,同时在预处理过程中,将字符串,整数,浮点型统一替换为0,这样对于缓冲区溢出等类型的代码是无法检测的,因为这些类型的漏洞需要精确的缓冲区空间大小(数组索引大小)