VDSimilar: Vulnerability detection based on code similarity of vulnerabilities and patches
来源信息
- 机构:中国科学院大学、山东师范大学、广西师范大学
- 作者:Hao Suna, Lei Cui, Lun Li, Zhenquan Ding, Zhiyu Hao,Jiancong Cui, Peng Liu
- 期刊:Computers & security(CCF B)
摘要
现有的研究是将漏洞挖掘看作二分类任务,但是这需要大量的标记数据,去学习代码中的语法和语义上的相似性。文章认为漏洞的相似性是检测的关键。文章提出了基于BiLSTM算法的孪生网络检测模型,学习漏洞-漏洞,漏洞-补丁之间的差异,为了提高检测能力,引入了注意力机制。在OpenSSL和Linux的876个漏洞和补丁的数据集中,VDSimilar模型在OpenSSL的AUC值为97.17%(其中注意力机制的贡献为1.21%)优于现有的最先进的深度学习模型。
方法
启发
对于两个程序版本中同一CVE 的两个易受攻击的函数,尽管代码更改,但漏洞片段仍将保留。对于一个易受攻击的函数和相关的修补函数,无论代码如何更改,漏洞片段都将消失。因此,每组函数都可能提供一个 CVE 的漏洞特征。其次,从漏洞的角度来看,不同版本的两个易受攻击的函数应被视为相似的,即使它们会经历代码更改。另一方面,由于漏洞片段已被删除,因此应将漏洞函数及其修补函数(甚至在语法中看起来相似)视为不同。
为什么是代码片段而不是整个函数是漏洞检测的关键

在程序的版本迭代中,commit更改有很多的可能,如bug修复、性能优化或代码重构.因此,两个版本的相同函数在语法和语义上可能显示出很大的差异。另一方面,对于需要修复的漏洞,补丁可能只涉及少数甚至一个代码行,因此连续版本的脆弱函数和补丁函数在语法上高度相似。
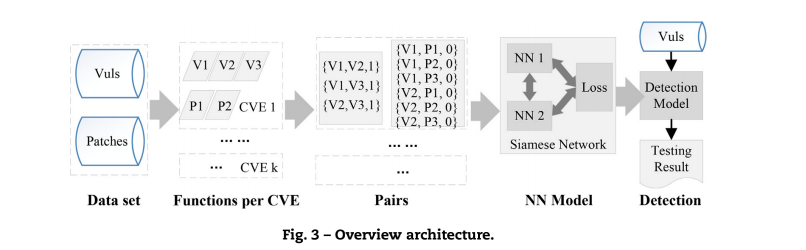
首先构建漏洞和补丁的数据库,构建漏洞-漏洞,漏洞-补丁对,标记漏洞对为1,漏洞补丁对为0,训练基于BiLSTM算法的孪生网络,从漏洞的角度学习两个代码的相似性和差异性,考虑到漏洞片段只占整个功能的一小部分,因此在模型中引入注意力机制,以关注真正脆弱的代码片段。
数据预处理
在采集数据过程中,通过CVE-ID去采集数据,然后通过漏洞描述去寻找相关的函数,进一步下载代码,提取出其中与漏洞相关的代码行。

实验
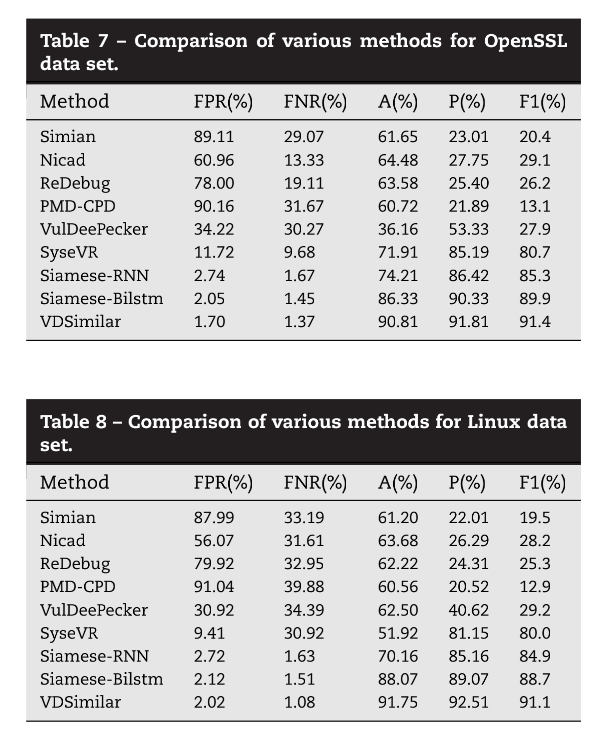
从图可以发现,无论是在Linux或者openssl数据集上,VDSimilar的效果都要优于其他的检测模型。
思考
- 该方法本质上还是将源代码视作文本,学习不同文本序列之间的差异性以检测漏洞。这种方法只考虑了token序列,未考虑控制依赖等语义信息。
- 检测能力有限,只能检测漏洞数据库中包含的指定类型漏洞,对于未知的漏洞无法检测。