Vulnerability Detection with Fine-Grained Interpretations
来源信息
- ESEC/FSE(CCF A)
- 机构:新泽西理工学院(USA)
- 作者:Yi Li; Shaohua Wang; Tien N. Nguyen
摘要
现有的漏洞检测技术大多只能检测代码片段是否存在漏洞,但是不能完成漏洞的定位。论文提出了IVDetect方法,通过PDG提取,并提取与漏洞语句有关的控制和依赖关系语句,利用FA-GCN对代码进行表征并进行分类。利用GNNExplainer对分类结果进行解释,从PDG中选取子图进行解释,如果评判子图对分类结果的重要性,来确定漏洞的具体的位置。
动机

上图是Linux内核中的一个漏洞,line-6,line-13的copy_from_user()利用指针从用户空间获取数据。line-6获取的值用于line-10的缓冲区分配,line-13将数据复制到s_cmd。也就是说line-6的u_cmd决定了line-13的s_cmd大小。但在多线程情况下,可能出现竞争条件,另一个用户的线程可能会更改line-13的u_cmd.in_size和out_size,当使用不一致的值时,会出现bug。
之前的方法,虽然可以检测出这段代码中的漏洞,但是无法定位出漏洞的具体位置,论文提出的IVDetect,不仅可以检测到漏洞,同时利用子图解释模型可以定位到具体的漏洞位置line-13.

论文方法
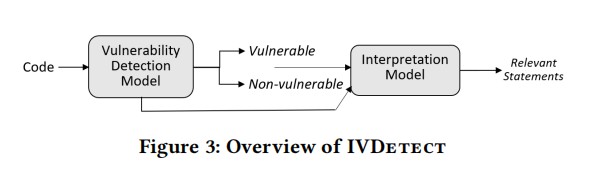
论文方法分为两个模块,漏洞检测模型:通过PDG提取漏洞语句相关的上下文,并利用GloVe和GRU完成源代码的特征表征。基于图的解释模块:主要任务是完成漏洞的定位,通过GNNExplainer对PDG子图进行解释并按照重要程度进行排序,对模型分类重要的语句就是漏洞产生的位置。
代码表征
在论文中的方法,作者提取了一下四种类型特征作为代码的表征
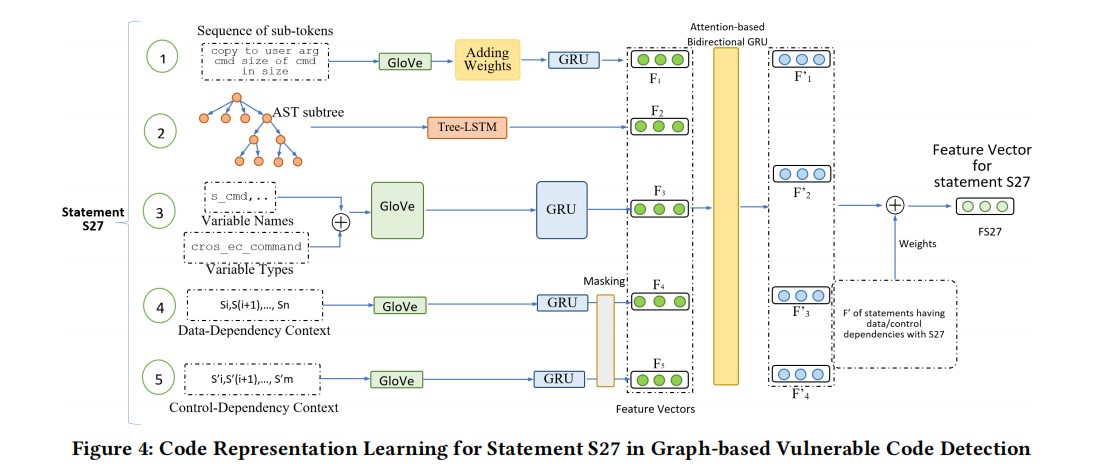
在论文中的方法,作者提取了一下五种类型特征作为代码的表征。
- subtoken的标记序列:将语句转成token序列,然后利用驼峰命名法进一步将token拆分成sub-token。利用GloVe将Token编码成向量,使用GRU生成subtoken标记序列的特征向量。GloVe可以很好地捕获subtoken之间的语义相似性。GRU可以很好的输出整条语句的特征向量。Token化的过程中只考虑变量、方法和类名,其他的都移除。
- 语句的代码结构:从AST中提取该语句的子树,然后利用Tree-LSTM生成语句结构的特征向量。
- 变量和类型:对于每一条语句,收集变量的名称和类型,利用1的方法拆分成sub-token,并使用GloVe编码成向量,GRU输出变量和类型的sun-token的特征向量。
- 数据依赖的上下文信息:对语句上下文有数据依赖的语句利用GloVe和GRU提取特征向量
- 控制依赖的上下文信息:对语句上下文有控制依赖的语句利用GloVe和GRU提取特征向量
特征融合:提取了上面的5个特征之后,利用带有注意力机制的BGRU将这些特征融合起来,作为该语句的代码表征F’,对于上下文每一个依赖语句都要计算一个F’,最后将这些F’加权求和得到最终的代码表征。
利用FA-GCN进行漏洞检测
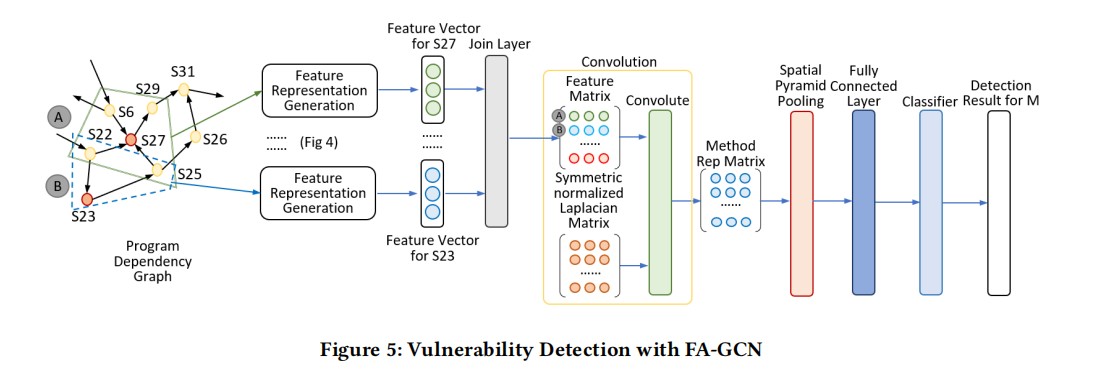
首先,构建函数的PDG,FA-GCN会沿着PDG的所有节点(语句)执行一个滑动窗口,窗口内的内容就是当前节点关联的语句,例如S27的窗口内容为{S6,S22,S25,S29},S23的窗口内容为{S22,S25},根据代码表征的方法,迭代窗口的节点生成最终的节点特征表示,最后将每条语句的特征向量连接起来,构成了代码片段的特征矩阵。
接着计算对称归一化拉普拉斯矩阵并利用CNN进行卷积,生成方法的表示矩阵,并连接其到一个全连接层将矩阵转换成向量,最后通过两个隐藏层和一个softmax函数进行分类
在CNN步骤中,传统的CNN需要输入的shape是一致的,但是漏洞挖掘场景中shape会有不同,因此论文采用的空间金字塔池化层解决这个问题。
基于图的解释模型
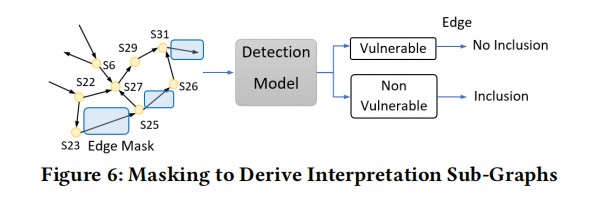
GNNExplainer将已经训练好的FA-GCN模型、方法M的PDG,预测结果和预测分数作为输入,然后通过输出一个子图以及该子图上更少的特征,表示其输出最大程度的影响了该GNN的预测结果。这个子图可以最大化与GNN预测结果的互信息。在这个过程中,会有一个图掩码,用于挑选真正重要的子图;一个特征掩码,用于挑选真正重要的子特征集。
论文利用GNNExclaner和edge-mask技术来实现漏洞的定位。其思想是最大化mask之后FA-GCN模型的输出差异。通过屏蔽掉PDG中的一些edge来判断这些edge对模型的检测是否重要。如果删除的边之后对模型的检测结果影响很大,说明该条edge很重要,反之对漏洞检测帮助不大。最后输出这些maskd edge的子图作为最终的模型解释。
实验
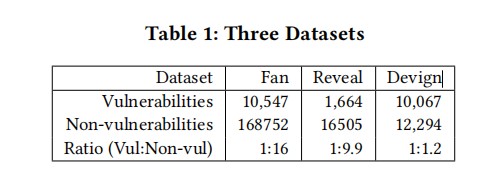
论文的数据集如下表所示
与现有的方法对比发现IVDetect在所有指标中都表现得更好。
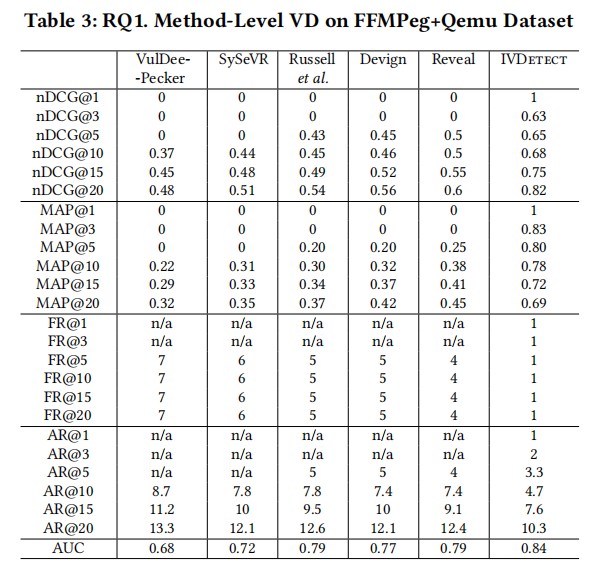
MAP多类平均精度,nDCG归一化折损累计增益(Normalized Discounted cumulative gain)
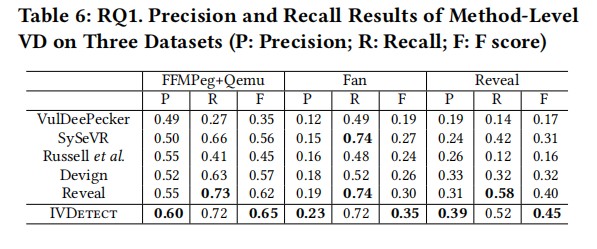
在三个数据集上的精度和召回率结果分析
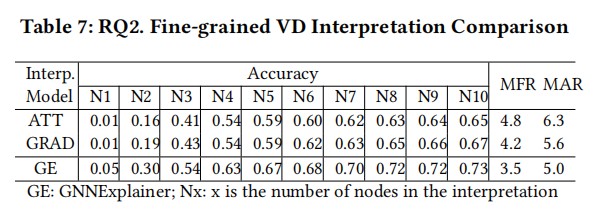
细粒度的VD解释比较
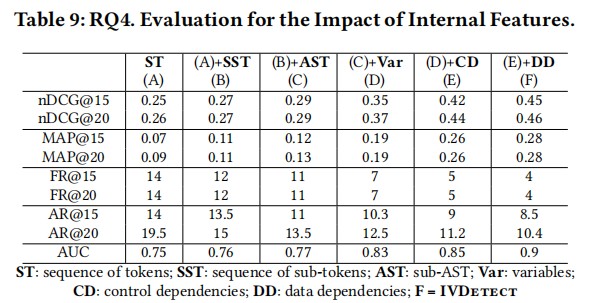
不同特征表征对模型的影响
总结
论文的核心目标是实现漏洞的检测和定位。相较于以前的方法,不同之处首先是在特征的表征过程中,利用漏洞上下文的数据和控制依赖信息、语句的Token语义,可以更加全面的表征漏洞的信息,挖掘漏洞语句的上下文依赖关系。第二点在于对漏洞的定位,现有的方法大部分都是在解决识别和分类的问题,很少有做定位的。文章利用基于图的解释模型实现漏洞的定位,通过GNNExplainer结合edge-mask找到漏洞触发的子图,实现漏洞的定位。这在现实场景中有很大的意义,可以帮助开发人员快速定位漏洞完成修复。