Finding Bugs Using Your Own Code: Detecting Functionally-similar yet Inconsistent Code
来源信息
- 机构:东北大学(USA)
- 作者:Mansour Ahmadi, Reza Mirzazade Farkhani, Ryan Williams, Long Lu
- Usenix 2021
摘要
对于同一个代码库来说,功能相似的代码片段,应该有着相似的形式。
对于一组功能相似但段形式不同的代码段,如果其中一个正常的话,则另一个有很大的可能存在bug。基于这个思想,作者提出了一种基于两步聚类的bug识别方法FICS,第一步:在粗粒度上聚类出功能相似的代码段,第二步:对第一步聚类出的簇进行更细粒度的聚类,找出功能相似而形式不一致的代码段,最后人工对偏差代码段进行分析,确定其中的bug,该方法并不特定于一种类型的不一致或bug,可以用于未知类型bug的检测。同时FICS在QEMU和OPENSSL等5个开源库中找到了22个新的bug。
背景
现有方法存在的问题
现有的基于机器学习的bug检测方法主要是通过训练大量的已有的bug样本,然后应用在项目中发现相似的bug。该方法存在两个问题。
- 训练需要大规模的已知bug,但是采集和清洗工作量巨大。
- 这类模型通常只能检测一个或几个特定类型的bug,对未知的bug无法检测。
启发
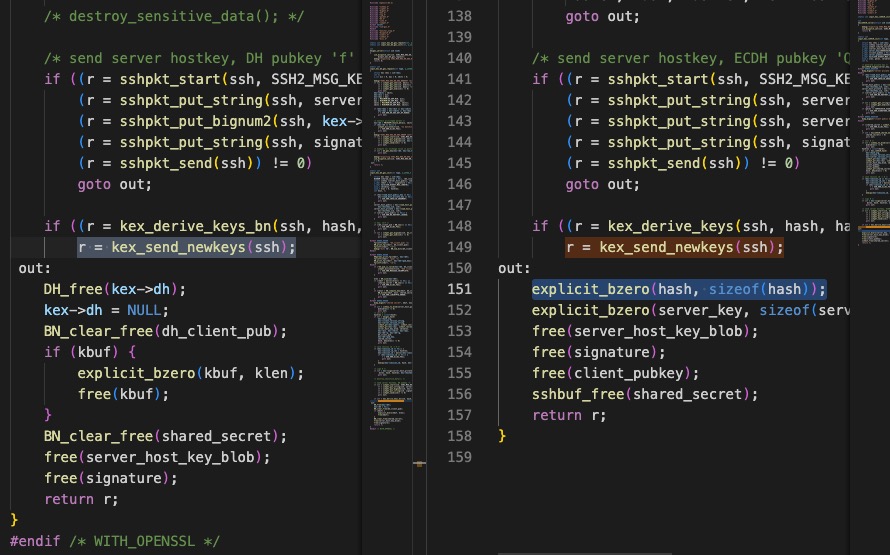
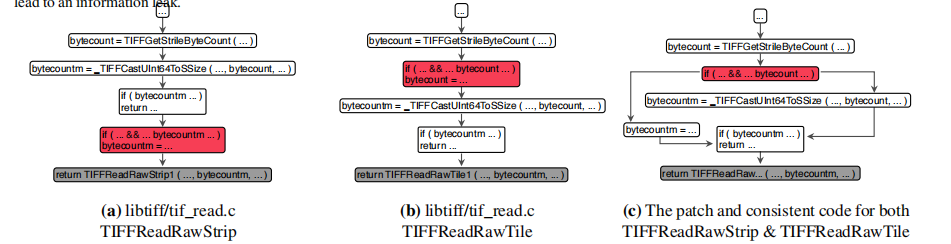
对于一个大项项目来说,通常存在很多功能相似的代码,当然大部分的代码形式也是相似的。当它们的形式不一样的时候,如果一个代码段正常(没有bug),那另一个有很大的可能存在着bug。论文中作者具了一个例子,我为了验证这个现象是否具有普遍性,自己去找了一个,十分钟我就在openssl找到了。
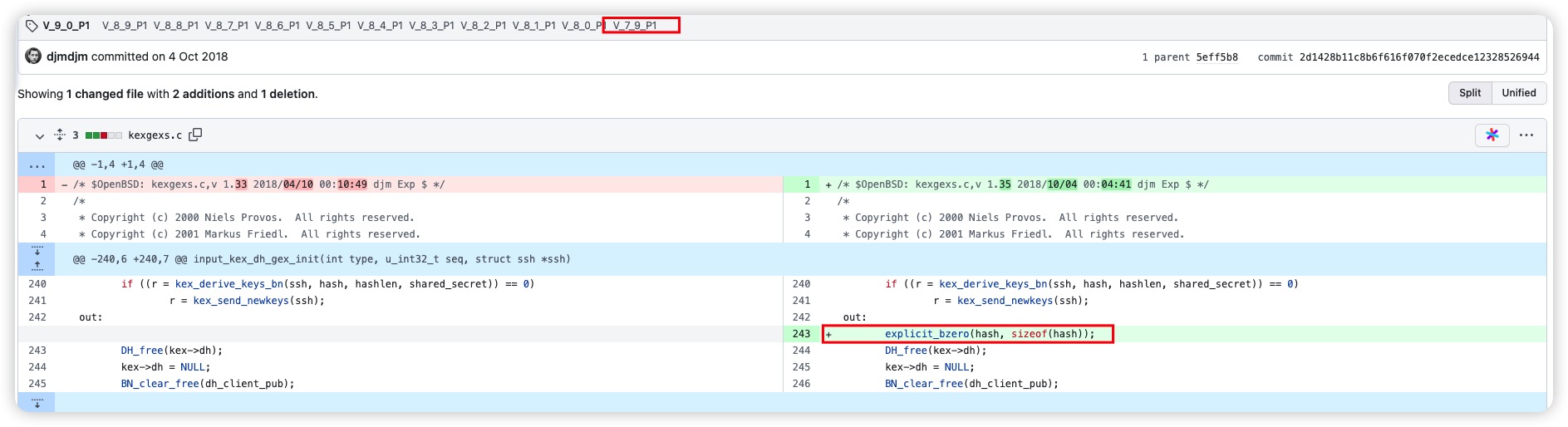
这是openssl存在的一个bug,影响“V_7_9_P1”以上版本,修复的方法就是添加了红框中的一行代码。我在上一个版本V_7_8的发行版代码中找到了这个漏洞,同时在不同文件中找到了相似的代码片段但却不存在bug(本身就包含补丁那句)。
FICS整体思路
作者对不一致是这样定义的:如果一组代码段的语义或逻辑是同义的,但是它们在实现上存在很大的不同,那么就称之为不一致。
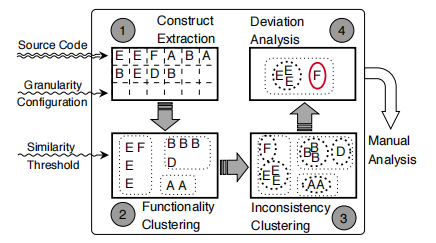
如图是FICS的工作流,首先这对源代码的Construct进行提取(该过程的重点是选择何种代码粒度才能有效的捕捉功能的一致性和形式的不一致性),然后对函数进行聚类找出其中功能一致性的代码片段,接着对每一个簇中的代码片段再进行聚类,区分出形式不一致的代码段,最后对偏离正常的代码段进行手工检测,最终确定bug。
具体方法
针对上面的代码粒度,作者选择过程间数据依赖图的子图。因为大部分的漏洞和补丁代码修改都发生在一个函数中,同时FICS关注过程间的不一致性,该粒度可以很好的聚类算法扩展到大型代码库。
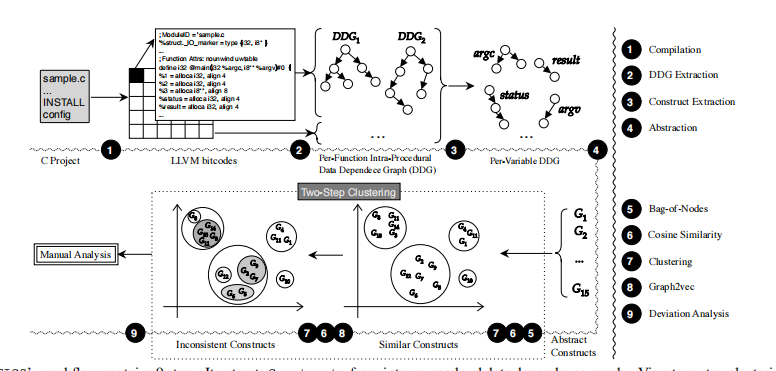
FICS主要包括9步,首先将源代码编译为LLVM bitcode方便后续的操作,然后提取每个函数的过程间DDG,接着针对DDG提取Construct,下一步对利用Bag-of-Nodes对提取的Construct进行粗粒度的嵌入进行第一步聚类,目的是对功能相似的Construct进行分组,然后使用Graph2Vec进行细粒度的嵌入,对每一个分组内部进行二次聚类,找出区别于其他Construct的Construct。最终人工对不一致的代码段进行分析确定bug。
代码表征和粒度选择
Q1: 为什么选择DDG作为代码的粒度?
- DDG本身就可以捕获导致大量bug的根本原因。例如,缺少检查,滥用api,错误的铸件,以及许多其他类型的bug,同时DDG相对于PDG等其他的表征形式更加的简单和高效。
- bug及其补丁通常出现在单个函数中,通过过程间的DDG就可以区分bug和正常代码的异同,去除与bug无关的代码,可以是FICS更加的高效,适用于大规模的项目检测。
- DDG可以很好的用于图嵌入。
Q2: Construct的定义?
Construct本质是DDG的子图,类似于程序切片。从一个指定的节点(根节点)开始遍历DDG,直到后续的所有节点都全覆盖或者到达Construct的最大深度,所有遍历的边和节点就组成了一个Construct。在一个函数中,所有的变量都可以作为根节点,因此Construct是一个Variable-based的DDG子图。Construct的最大深度本质就是DDG子图中节点的数量最大值,默认是无限的。
通过定义Construct就可以识别一致性的问题转变为检测单个变量在计算和操作上的相似和不一致性问题。作者进一步对Construct进行抽象化表示,删除语句中变量名,只保留变量类型,同时删除了常量和文本。因为这些内容对FICS无用,会影响后续的聚类。
分步聚类
第一步聚类(功能相似性聚类)
第一步聚类目的是找出同一个代码库中那些功能相似的代码,bug代码和补丁代码就具有很高的相似性,通常只是增加或删减了几行代码,或者代码顺序发生微调,(a),(b)就是同一函数的补丁前后代码,我们认为这就是相似的代码段,第一步的目的也就是将这类代码划分为一组,可以发现如果不考虑代码的前后顺序的话,(a)(b)的相似度就非常高,因此在第一步聚类的过程中,FICS不考虑边的信息,直接将Block利用NLP技术进行嵌入,同时利用connected-component algorithm完成聚类。
第二步聚类(不一致聚类)
第二步聚类的目的是找出功能相似但不一致的代码段,这就需要更细粒度的表征了,论文利用Graph2Vec来完成嵌入,其可以很好的表征代码的图结构语义信息,包括节点以及调用关系等。聚类算法同上一步。
实验
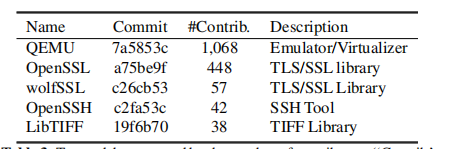
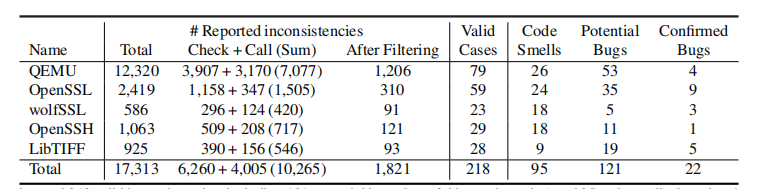
数据集来自主流的5个开源项目
FICS的检测能力优于APIsan, LRSan, Crix
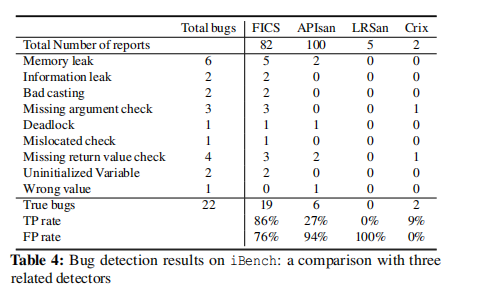
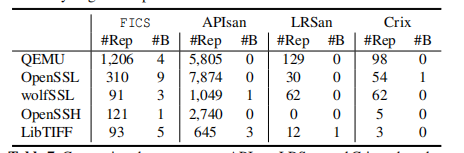
FICS可以检测到未知的bug,检测到了218个不一致的代码,其中22已经被厂商确认
局限
- FICS目前只能检测相似代码的不一致性bug,不能检测那些没有相似函数的bug代码。
- Construct并不适用于所有的bug,有的bug可能只是一行代码,粒度太小。同时Construct是函数内的,因此无法检测那些跨函数导致的bug。
- FICS不支持C++代码检测。